
(이 글을 적는 가장 큰 목적은 여러 상황(JPA, JPQL, Nativa Query, @Transactional 의 조합) 에서 쿼리가 어떻게 날아가는지 보는 것이기에, 영속성 컨텍스트에 대한 자세한 설명은 하지 않을 예정입니다.)
JPA를 배우면 영속성 컨텍스트에 대해 배우게 된다.
영속성 컨텍스트에 대해 간단히 설명하면 , "애플리케이션과 DB 사이에 영속화된 엔티티를 관리하는 논리적 공간" 으로 정의할 수 있다.
영속화란 엔티티를 영속성 컨텍스트가 관리할 수 있게 만드는 것이다.
영속성 컨텍스트에 대해 간단히 알아보자.
영속성 컨텍스트에 대한 간단한 공부
영속성 컨텍스트는 DB로의 접근을 최소화고, 동일한 엔티티의 동등성을 보장하기 위해
다음 4가지 기능을 제공한다.
1. 1차 캐시
개발자가 DB에 특정 엔티티를 조회하면 해당 엔티티의 키를 PK, 밸류를 엔티티로 해서 캐싱을 한다.
이렇게 저장되는 것을 1차 캐시라고 한다.
왜 중요할까?
개발자가 DB에 조회 요청을 보낼 시 , 조회하려는 엔티티가 1차 캐시에 있다면 실제 DB에 쿼리를 날리지 않고 , 1차 캐시에서 가져온다.
-> 불필요한 쿼리가 줄어든다.
2. 쓰기 지연 저장소
특정 코드를 변경하는 쿼리가 하나의 메서드 안에 많으면 어떻게 될까?
메서드를 실행하면 여러번 쿼리가 나갈 것이다.
쓰기 지연 저장소는 DB에 변화를 일으키는 쿼리를 모아두었다가 flush()가 발생하는 경우 한 번에 보내준다.
이를 통해 DB와 여러 번 통신할 필요가 없어진다.
3. Dirty Check
1차 캐시는 키 : id , 밸류 : entity의 형태로 엔티티를 저장한다고 했다.
JPA는 1차 캐시에 엔티티를 캐싱할 때 초기 상태 그대로 스냅샷을 만든다.
개발자가 엔티티에 대한 수정을 하면, 1차 캐시 엔티티의 값을 변경한다.
JPA는 개발자가 flush()를 할 때 1차 캐시 엔티티와 스냅샷을 비교한다.
수정된 부분이 있다면 수정 쿼리를 쓰기 지연 저장소에 저장하고, SQL을 DB로 전송한다.
4. Lazy Loading
Lazy Loading은 연관관계에 있는 엔티티들을 프록시 객체로 가져왔다가, 필요할 때 실제 DB에 요청을 보내는 것을 의미한다.
(프록시 객체는 실제 엔티티를 상속받아 만들어진 가짜 객체로, 실제 객체에 대한 참조를 보관하고 있다.)

ORM을 통해 높은 성능을 이뤄내는 방법은 DB로의 접근을 최소화 하는 것이다.
하이버네이트를 통해 데이터에 접근하는 코드를 작성할 땐 항상 위 점을 유의해야 한다.
이제 여러 상황을 함께 보며 쿼리가 어떻게 날아가는지 예측해보자.
실습해보기
Prerequisite
전체 코드는 깃허브에서 볼 수 있습니다.
https://github.com/HoyeongJeon/blog-code/tree/main/jpapractice
Entity
@Entity
@Table(name = "member")
public class Member {
@Id
private Long id;
@Column(name = "name")
private String name;
@Column(name = "age")
private Integer age;
public Member(Long id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
protected Member() {
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query(value = "SELECT * FROM member WHERE id = :id", nativeQuery = true)
Member findByIdWithNative(@Param("id") Long id);
@Query("SELECT m FROM Member m WHERE m.id = :id")
Member findByIdWithJPQL(@Param("id") Long id);
}
Service
@Service
public class MemberService {
private final MemberRepository memberRepository;
@PersistenceContext
private EntityManager entityManager;
public MemberService(MemberRepository memberRepository, EntityManager entityManager) {
this.memberRepository = memberRepository;
this.entityManager = entityManager;
}
@Transactional
public void insertMembersForTest() {
memberRepository.save(new Member(1L, "Alice", 30));
memberRepository.save(new Member(2L, "Bob", 25));
}
@Transactional
public void testAnnotation() {
...
}
public void testNoneAnnotation() {
...
}
@Transactional
public void testJPA() {
...
}
@Transactional
public void testJPQL() {
...
}
@Transactional
public void testNativeQuery() {
...
}
@Transactional
public void testFlush() {
...
}
@Transactional
public void testHell() {
...
}
}
이제 각 메서드가 어떻게 쿼리를 보내는지 알아보자.
@Transactional + JPA
@Transactional
public void testAnnotation() {
System.out.println("// testAnnotation start");
Member member = memberRepository.findById(1L).get();
member.setAge(35);
memberRepository.save(member);
}
쿼리가 어떻게 나갈까?
연습장에 적어보거나 , 생각해보길 추천한다.
아래는 답!
답이에요!!! 👇

select
update
이렇게 쿼리가 나갔다.
JPA만 사용하기(@Transactional 이 없는 경우)
public void testNoneAnnotation() {
System.out.println("// testNoneAnnotation start");
Member member = memberRepository.findById(1L).get();
member.setAge(35);
memberRepository.save(member);
System.out.println("result: " + member.getAge());
}
쿼리가 어떻게 나갈까?
현재 @Transactional 어노테이션이 없다!
또 나이는 과연 어떻게 바뀔까? (기존 Member 나이 : 30)
아래는 답!
답이에요!!! 👇

select
select
update
이렇게 쿼리가 나갔고,
나이는 35로 바뀌었다!
위 질문에 대한 답은 좀 길어서 따로 정리했으니 다음 글을 보면 된다!!
https://securityinit.tistory.com/255
JPA의 save()가 어떻게 동작하는지 궁금해졌다.
JPA의 쿼리가 어떻게 날아가는지 여러 방면으로 공부하다 save() 동작에 대한 의문이 생겼다.그래서 깊게 알아보려 한다.( 전체 코드 👉🏻 https://github.com/HoyeongJeon/blog-code/tree/main/howsavework )고민의
securityinit.tistory.com
@Transactional + JPA
@Transactional
public void testJPA() {
System.out.println("// testJPA start");
Member member1 = memberRepository.findById(1L).get();
Member member2 = memberRepository.findById(1L).get();
System.out.println("result" + (member1 == member2));
}
쿼리가 어떻게 나갈까?
연습장에 적어보거나 , 생각해보길 추천한다.
아래는 답!
답이에요!!! 👇
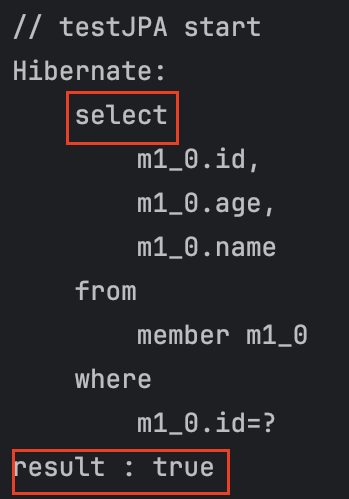
select
result : true
결과는 간단하다.
Member member1 = memberRepository.findById(1L).get();
이 쿼리에서 select가 나간다.
여기서 가져온 엔티티를 1차 캐시에 저장하고,
Member member2 = memberRepository.findById(1L).get();
여기선 1차 캐시에 캐싱된 엔티티를 가져온다.
그렇기에 쿼리가 한 번만 나갔고, 두 값이 같다고 나온다!(영속성 컨텍스트의 동일성 보장)
@Transactional + JPQL
1.
@Transactional
public void testJPQL() {
System.out.println("// testJPQL start");
Member member1 = memberRepository.findById(1L).get();
Member member2 = memberRepository.findByIdWithJPQL(1L);
System.out.println("result" + (member1 == member2));
}
2.
@Transactional
public void testJPQL() {
System.out.println("// testJPQL start");
Member member2 = memberRepository.findByIdWithJPQL(1L);
Member member1 = memberRepository.findById(1L).get();
System.out.println("result : " + (member1 == member2));
}
1번과 2번 각각 쿼리가 어떻게 나갈지 연습장에 적어보거나, 생각해 보길 추천한다.
아래는 답!
1번 답
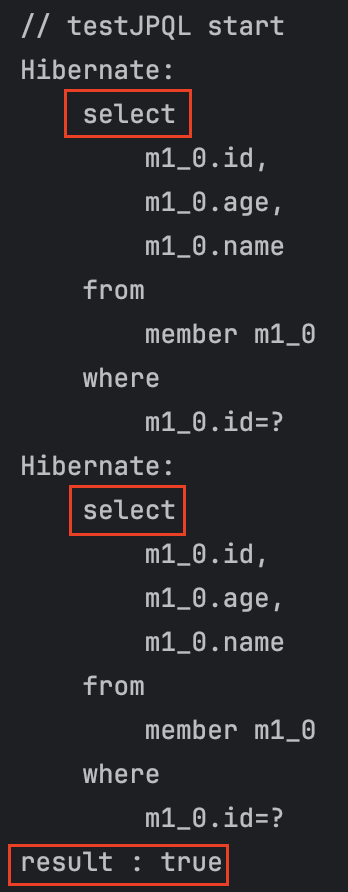
select
select
result : true가 나온다.
2번 답
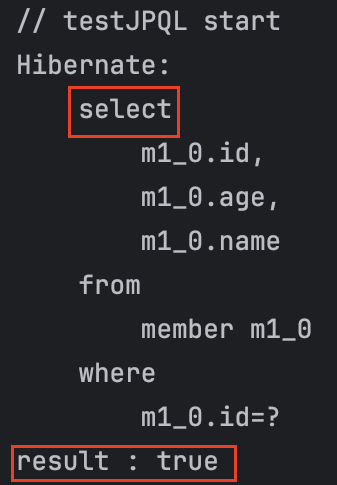
select
result : true가 나온다.
1번과 2번 나간 쿼리가 다르다.
1번에선 왜 select가 2번 나갔을까?
1번 코드
@Transactional
public void testJPQL() {
System.out.println("// testJPQL start");
Member member1 = memberRepository.findById(1L).get();
Member member2 = memberRepository.findByIdWithJPQL(1L);
System.out.println("result" + (member1 == member2));
}
Member member1 = memberRepository.findById(1L).get();이때 jpa가 db로 쿼리를 보낸다. (1차캐시에 값이 없기 때문!)
그런데 그 뒤에 쿼리가 한번 더 나갔다.
Member member2 = memberRepository.findByIdWithJPQL(1L);
여기서 쿼리가 나갔다.
즉 , flush가 발생한 것이다.
flush는 다음과 같은 경우에 발생한다.
em.flush() 직접 호출
트랜잭션 커밋
JPQL 쿼리 실행
Native 쿼리 실행 (Spring 2.3.x 이후 버전 사용할 때)
1차 캐시에 이미 동일한 엔티티가 있어도 JPQL을 사용하면 무조건 쿼리를 날린다는 뜻이다.
(설명을 덧붙이면.. JPQL은 1차 캐시 존재 여부와 무관하게 JPQL은 항상 DB를 조회하지만, 1차 캐시에 엔티티가 있으므로, 해당 엔티티를 재사용한다!!)
이제 2번에선 왜 쿼리가 한 번만 나갔는지 알 수 있을 것이다.
2번 코드
@Transactional
public void testJPQL() {
System.out.println("// testJPQL start");
Member member1 = memberRepository.findByIdWithJPQL(1L);
Member member2 = memberRepository.findById(1L).get();
System.out.println("result : " + (member1 == member2));
}
Member member1 = memberRepository.findByIdWithJPQL(1L);이때 JPQL이 DB에 쿼리를 날리고, 결과 엔티티를 1차 캐시에 적재(이미 존재한다면 병합)한다.
Member member2 = memberRepository.findById(1L).get();여기선 JPA가 1차캐시에 찾으려는 엔티티가 있으므로, 쿼리를 날리지 않고, 1차 캐시에 있는 값을 가져온다.
그러므로 쿼리가 한 번만 나갔고, true가 나온 것이다.
flush가 발생하는 조건을 잘 생각해서 코드를 작성해야 한다.
flush가 무조건 발생하는 경우를 먼저 둬야, 불필요한 쿼리를 줄일 수 있다!
@Transactional + NativeQuery
@Transactional
public void testNativeQuery() {
System.out.println("// testJPQL start");
Member member1 = memberRepository.findById(1L).get();
Member member2 = memberRepository.findByIdWithNative(1L);
System.out.println("result : " + (member1 == member2));
}쿼리가 어떻게 나갈까?
연습장에 적어보거나 , 생각해보길 추천한다.
아래는 답!
답이에요!!! 👇
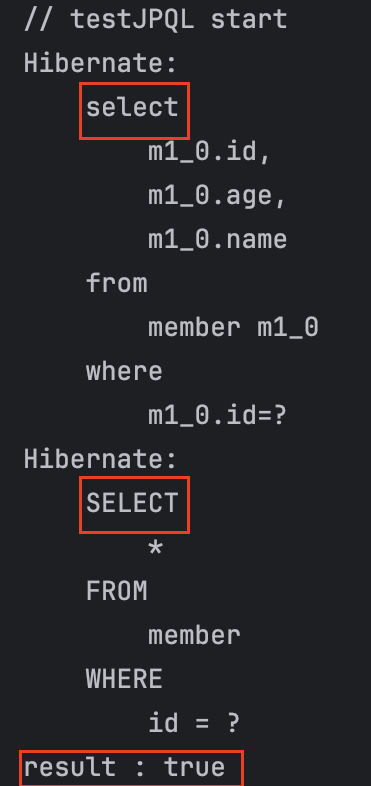
select
select
result : true가 나온다.
이번 문제는
@Transactional + JPQL 과 같은 풀이이다!
(native 쿼리도 영속성 컨텍스트를 거치지 않고 바로 DB에 쿼리를 날리지만, 결과 엔티티는 1차 캐시에 병합한다!)
@Transactional + flush
@Transactional
public void testFlush() {
System.out.println("// testFlush start");
Member member = memberRepository.findById(1L).get();
member.setAge(35);
entityManager.flush();
System.out.println("result : " + member.getAge());
memberRepository.save(member);
}쿼리가 어떻게 나갈까?
연습장에 적어보거나 , 생각해보길 추천한다.
아래는 답!
답이에요!!! 👇

select
update
result : 35 가 나왔다.
@Transactional
public void testFlush() {
System.out.println("// testFlush start");
Member member = memberRepository.findById(1L).get();
member.setAge(35);
entityManager.flush();
System.out.println("result : " + member.getAge());
memberRepository.save(member);
}
Member member = memberRepository.findById(1L).get();일단 여기서 select 쿼리가 나갔다.
member.setAge(35);이 부분에서 update 쿼리가 쓰기지연 저장소에 저장된다.
entityManager.flush();
중간에 강제로 flush를 했으므로, 쓰기지연 저장소의 update 쿼리가 날아간다.
flush를 해도 영속성 컨텍스트가 비워지는 것은 아니다!!
1차 캐시엔 그대로 값이 남아있다.
System.out.println("result : " + member.getAge());
memberRepository.save(member);
그러므로 age가 35가 나왔다.
그리고 save를 하고 트랜잭션이 종료되며 커밋이 되어도, 쓰기 지연 저장소엔 값이 없기에 추가 쿼리가 날아가지 않는다.
최종 문제
@Transactional
public void insertMembersForTest() {
memberRepository.save(new Member(1L, "Alice", 30));
memberRepository.save(new Member(2L, "Bob", 25));
}
------------------------------ 아래부터 문제 ------------------------------
@Transactional
public void testHell() {
Member alice = memberRepository.findById(1L).get();
Member bob = memberRepository.findById(2L).get();
alice.setAge(40);
memberRepository.delete(bob);
Member newAlice = memberRepository.findByIdWithJPQL(1L);
Member newBob = new Member(2L, "Bob", 99);
entityManager.persist(newBob);
entityManager.flush();
Member nativeBob = memberRepository.findByIdWithNative(2L);
memberRepository.save(newAlice);
memberRepository.save(nativeBob);
System.out.println("newAlice 나이는 ? : " + newAlice.getAge());
System.out.println("nativeBob 나이는 ? : " + nativeBob.getAge());
}
쿼리가 어떻게 나갈까?
연습장에 적어보거나 , 생각해보길 추천한다. (앞에 함께 공부했던 내용을 찬찬히 생각하며 풀면 답이 나온다!)
아래는 답!
답이에요!!! 👇

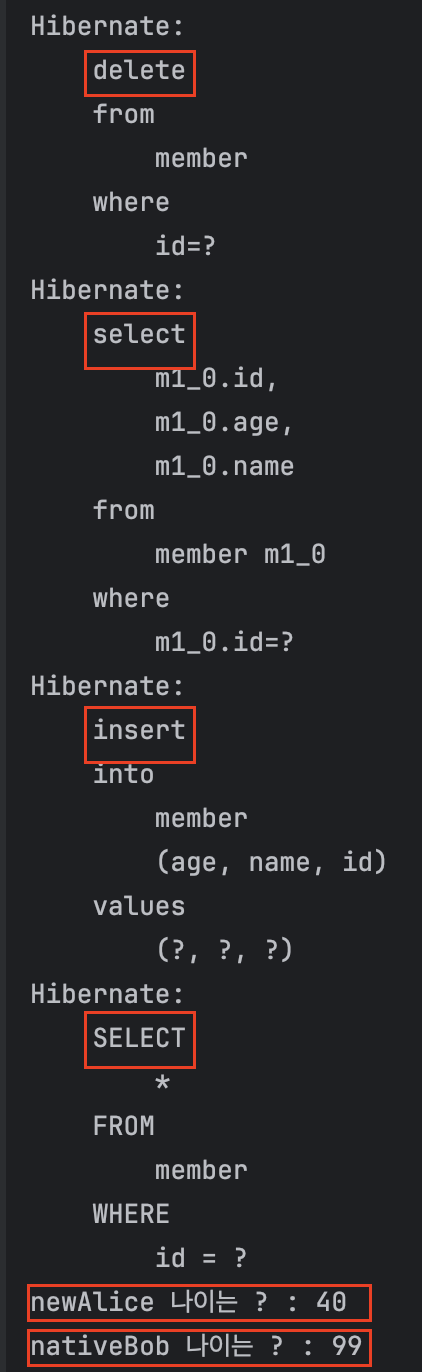
select
select
update
delete
select
insert
select
newAlice 나이 : 40
nativeBob 나이 : 99
하나씩 살펴보자.
(쿼리가 날아간 경우를 파란색으로 표시했다)
@Transactional
public void testHell() {
System.out.println("// testHell start");
Member alice = memberRepository.findById(1L).get();
Member bob = memberRepository.findById(2L).get();
alice.setAge(40);
memberRepository.delete(bob);
Member newAlice = memberRepository.findByIdWithJPQL(1L);
Member newBob = new Member(2L, "Bob", 99);
entityManager.persist(newBob);
entityManager.flush();
Member nativeBob = memberRepository.findByIdWithNative(2L);
memberRepository.save(newAlice);
memberRepository.save(nativeBob);
System.out.println("newAlice 나이는 ? : " + newAlice.getAge());
System.out.println("nativeBob 나이는 ? : " + nativeBob.getAge());
}
Member alice = memberRepository.findById(1L).get();
Member bob = memberRepository.findById(2L).get();일단 여기서 select 쿼리가 2번 나간다. (1차 캐시는 현재 아무 엔티티도 없다.)
alice.setAge(40);
memberRepository.delete(bob);
여기서 update, delete 쿼리가 쓰기 지연 저장소에 적재된다.
Member newAlice = memberRepository.findByIdWithJPQL(1L);JPQL로 쿼리를 날리면 그 전에 커밋이 된다고 앞에서 공부했다!
그러므로 쓰기지연 저장소에 있는
update
delete
쿼리가 날아간다.
그 후 select(JPQL) 가 날아간다.
Member newBob = new Member(2L, "Bob", 99);
entityManager.persist(newBob);
entityManager.flush();
여기서 newBob이 db에 저장된다. (insert)
Member nativeBob = memberRepository.findByIdWithNative(2L);Natvie 쿼리를 날렸으므로 여기서도 select 쿼리가 나간다.
memberRepository.save(newAlice);
memberRepository.save(nativeBob);
이전 native 쿼리를 날리면서 커밋이 한번 진행되므로, 현재 쓰기 지연 저장소엔 아무 쿼리가 없다.
그러므로 @Transaction이 끝나더라도 날아갈 쿼리가 없다!
System.out.println("newAlice 나이는 ? : " + newAlice.getAge());
System.out.println("nativeBob 나이는 ? : " + nativeBob.getAge());
나이도 alice는 40 , bob은 99로 변경되었다.
Member newAlice = memberRepository.findByIdWithJPQL(1L);여기서 나이가 변경된 Alice를 가져왔고, 이 값을 1차 캐시에 캐싱했다.
Member newBob = new Member(2L, "Bob", 99);
여기서 나이가 변경 된 Bob을 1차 캐시에 캐싱했다.
그 후 영속성 컨텍스트가 clear() 된 적 없으므로, 1차 캐시엔 계속 나이가 변경 된 Bob이 남아있다.
(1차 캐시는 PK와 엔티티를 맵핑한다!
newBob, nativeBob 이렇게 불러왔지만 각 엔티티의 PK가 동일하므로 같은 엔티티가 1차 캐시에 저장되어 있다!)
그러므로 Alice와 Bob의 나이는 40, 99가 나온다.
긴 코드를 다시 정리해보자.
@Transactional
public void testHell() {
System.out.println("// testHell start");
Member alice = memberRepository.findById(1L).get(); // select(alice)
Member bob = memberRepository.findById(2L).get(); // select(bob)
alice.setAge(40); // update
memberRepository.delete(bob); // delete
// flush 발생!!! JPQL 나가기 전이니까!! 그러므로 update, delete가 나감.
Member newAlice = memberRepository.findByIdWithJPQL(1L); // select
Member newBob = new Member(2L, "Bob", 99);
entityManager.persist(newBob); // newBob 영속화
entityManager.flush(); // insert (newBob), flush를 했으므로 쓰기 지연 저장소가 비워짐.
Member nativeBob = memberRepository.findByIdWithNative(2L); // select(nativeBob). 1차 캐시에 있는 값과 동일한 엔티티이므로 1차캐시엔 변화가 없다.
memberRepository.save(newAlice);
memberRepository.save(nativeBob);
// 현재 1차 캐시
// 1. alice (나이 40)
// 2. bob (나이 99)
System.out.println("newAlice 나이는 ? : " + newAlice.getAge());
System.out.println("nativeBob 나이는 ? : " + nativeBob.getAge());
} // Transaction이 끝나도 쓰기 지연 저장소에 남아있는 쿼리가 없으므로 아무 쿼리도 안날아감!
정리
가장 중요한 것은 "flush가 언제 나가느냐" 이다.
em.flush() 직접 호출
트랜잭션 커밋
JPQL 쿼리 실행
Native 쿼리 실행 (Spring 2.3.x 이후 버전 사용할 때)
위 상황에서 무조건 flush가 나간다.
그러므로 쿼리를 작성할 때 불필요한 쿼리를 날리지 않도록 순서를 잘 고려해서 쿼리를 작성하자!