
이 글을 쓰게 된 계기
큐시즘 31기 기업프로젝트에서 서울우유의 업무 프로세스 개선 프로젝트를 하게되었다.
우리가 개선하고 한 프로세스에 대해 간단히 소개하면...
기존 업무 프로세스

- 서울우유의 대리점은 마트, 슈퍼에 납품을 한다.
- 본사에서는 판매량 증가를 통한 이윤 상승을 위해→ 대리점이 저렴하게 납품을 하도록 한다. (할인해서 납품)
- 이후 대리점은 납품한 내역(세금계산서)을 본사에 제출한다.
- 본사는 국세청 홈택스 사이트에서 세금계산서의 *진위여부를 확인한다.
- 맞다면, 지급결의서를 작성한다.
- 이후 본사에서는 지급결의서의 내용대로 대리점에게 금액을 지급한다.
그런데 이 과정을 직원들이 수기로 하고 있었다.
대리점에서 전달받은 세금계산서를 서울우유 지점 엄부 담당자가 국세청 홈택스 사이트에서 진위여부를 확인한다. (<- 이 과정은 수기로 반복한다.)
진위여부가 참으로 밝혀진 세금 계산서에 대해 담당자가 수기로 비용 지급을 위한 지급 결의서를 작성한다.
결국 이 과정을 사람이 수기로 작성하다보니,
- 단순 반복적인 업무에 의한 업무 비효율
- 사람이 수기로 작성함으로 인해 발생하는 휴먼 오류
위 두 문제를 겪고 있었다.
우리가 수정하고자 하는 방향
가장 큰 문제는 수기로 작성하는 부분이었다.
사람이 직접 하나씩 보면서 값을 작성하고, 이를 검증하고 이런 작업을 없애기 위해 해당 작업을 자동화하는 것이 우리의 목표였다.
그래서 다음 그림과 같은 방식으로 수정 방향을 잡았다!

여기서 핵심은 아래 사진 부분이다.

- 세금계산서 업로드
- 세금계산서의 텍스트 추출
- 해당 텍스트를 국세청 API로 연동해 진위여부 판단
이 과정을 위해 다음과 같은 기술을 사용하기로 결정했다.
- 세금계산서 업로드 & 세금계산서의 텍스트 추출 -> Naver Clova OCR
- 해당 텍스트를 국세청 API로 연동해 진위여부 판단 -> Codef API
1에서 2로 넘어가는 과정을 사용자의 액션 없이 자동화하려 했고, 이 과정에서 이벤트 기반 파이브라인을 구성하려 했다.
이 과정에서 Kafka 를 사용하기로 결정했다.
왜 카프카를 선택했는가?
이벤트 기반 아키텍처를 구성하는데 , 다음과 같은 선택지가 있었다.
- EventPublisher
- RabbitMQ
- Redis Pub - Sub
- Kafka
각각의 요소를 살펴보고, 왜 카프카를 선택했는지 살펴보자.
1. EventPublisher
대부분의 Pub - Sub 구조가 그렇듯 , Spring Event Publisher 는 다음과 같은 형태로 동작한다.
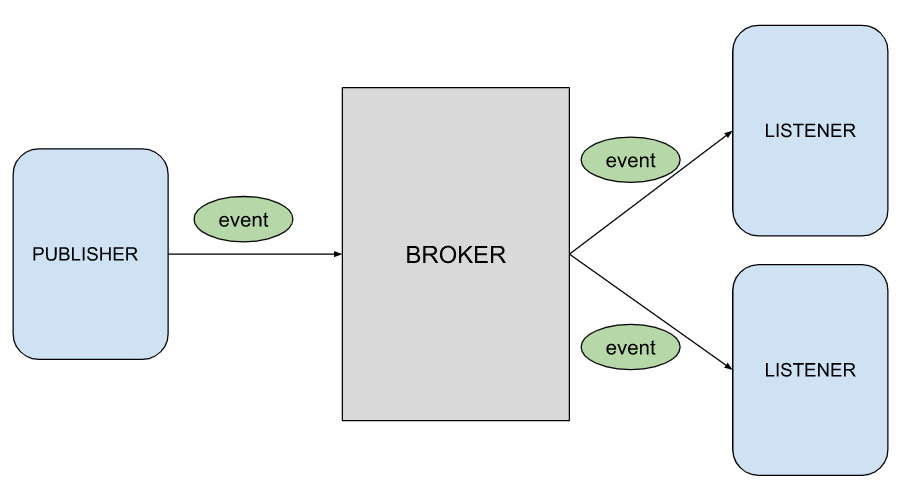
Publisher 가 이벤트를 발행하고, 브로커가 해당 이벤트를 리스너에게 뿌려준다.
기본적으로 내가 구현하고자 한 방향과 일치한다.
그러나 EventPublisher 는 이벤트를 발행하면 바로 리스너에게 전달한다. 별도로 이벤트를 저장하지 않는다.
이런 경우, 모종의 이유로 서버가 다운된다면 이벤트도 함께 사라진다.
세금계산서 검증 플로우의 가장 중요한 점은 Falut tolerence 라고 생각했다.
그러기에 서버가 다운되면 이벤트도 함께 사라지는 스프링의 Event Publisher 는 우리의 기술 결정에서 제외했다.
-2025.05.19-
Spring Modulith 라는 대체제가 있었다.
일반적인 Spring Event 시스템은 이벤트를 저장하진 않지만, Spring Modulith 는 이벤트 저장 및 관리가 가능하다고 한다.
2. Rabbit MQ
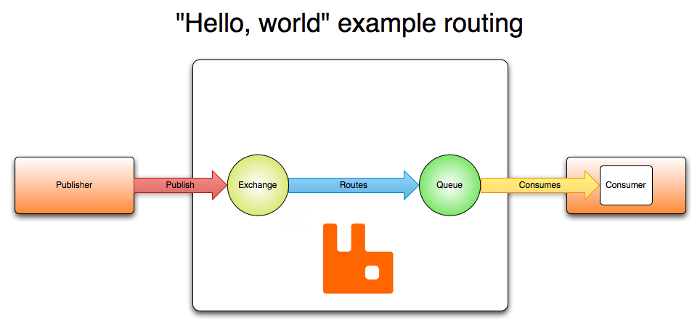
Rabbit MQ 는 이벤트가 퍼블리싱 되면 Exchange가 해당 이벤트를 어떤 큐로 전달할 지 결정해 라우팅한다.
그러나 Rabbit MQ 는 Event Consumer가 queue 에 저장된 메시지(이벤트)를 가져가면, queue 에서 해당 메시지(이벤트)를 삭제한다.
우리가 원하는, 이벤트가 소비되어도 계속 남아있는 형태완 다르기에 Rabbit MQ를 우리 기술 선택에서 제외했다.
3. Redis Pub - Sub

레디스의 pub - sub의 경우, 매우 빠르게 동작한다.
그러나 구조가 단순하게 되어있고, publish 한 메시지는 따로 보관되지 않으며 subscriber 가 수신했는지는 확인하지 않는다.
그러다보니 메시지를 빠르게 publish 하고 싶을 때, 그러나 100% 전송 보장이 되지 않아도 되는 케이스에 사용하기 좋다.
우리의 케이스는 100% 전송 보장이 되어야 하기에, Redis Pub - Sub 도 우리 기술 선택에서 제외했다.
4. Kafka

카프카의 경우 , 이벤트가 토픽에 남아있다.
이벤트가 Topic 내부에 순서대로 남아있고, 이벤트가 처리되었더라도, 토픽 내부에서 사라지지 않는다.
또한 오프셋을 통해 어디까지 이벤트가 처리되었는지 알 수 있다.
그러기에 모종의 이유로 서버가 다운되어도 , 토픽을 보면 어떤 이벤트까지 처리했는지 알 수 있으므로, 우리의 목적에 가장 일치했다.
이러한 이유로 카프카를 사용하기로 결정했다.
아파치 카프카 용어 정리
(이 문단은 카프카에 대한 이론적 내용이므로, 관심이 없다면 다음 문단으로 넘어가면 된다.)
카프카를 전부 설명하기엔 지식이 짧고, 모든 것을 설명할 능력도 없다.
카프카에 대한 설정, 트러블 슈팅 등을 설명할 때 카프카 용어를 사용하게 될 예정이기에, 해당 용어들에 대한 설명을 미리 하고 넘어가려 한다.
먼저 카프카 공식문서에 들어가면, 다음과 같은 설명을 볼 수 있다.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
고성능의 분산 이벤트 스트리밍 플랫폼이다.
우리가 원하는 이벤트 pub-sub 구조를 가지고 있다.
(카프카에선 producer - consumer 이다.)

카프카를 공부하면 위와 같은 아키텍쳐를 보게 된다. 위 아키텍처를 보며 용어들에 대해 간단히 알아보자.
각 설명 아래 이해를 돕기 위해 도서관과 비유해서 적어보았다.
정확한 1:1 매핑이라기보단, 각 역할을 더 쉽게 이해하기 위한 비유이므로, 1:1로 정확히 매핑된다 생각하면 안된다!
Producer
- 이벤트를 발행하는 주체이다.
- "책을 쓰는 작가"와 같다.
Consumer
- 이벤트를 소비하는 주체이다.
- "도서관에서 책을 빌려 읽는 독자" 와 같다.
Topic
- 이벤트를 저장하는 폴더와 같다.
- 메시지(이벤트)를 카테고리화 하는 논리적인 개념이다.
- "도서관의 책 주제"와 같다.
Partition
- 토픽 내의 물리적인 데이터 분할 단위를 의미한다.
- 토픽은 여러 개의 파티션으로 구성된다.
- "각 주제별 책장" 과 같다.
Broker
- 카프카 클러스터 내부에 있는 개별 서버
- 토픽의 파티션을 저장하고 관리한다.
- "도서관의 분관"과 같다. (각 분관엔 여러 책이 있고, 독자는 각 분관에 가서 책을 빌릴 수 있다!)
Kafka Cluster
- 여러 kafka 브로커를 관리한다.
- 데이터를 여러 브로커에 분산 저장해주며 부하를 분산시키고, 프로듀서와 컨슈머 사이의 메시지를 전달한다.
- "도서관 건물" 이라고 생각하면 된다.
Zookeeper
- 카프카 클러스터가 안정적으로 운영되도록 관리한다.
- "도서관 관리 시스템"이라 생각하면 된다. (도서관의 여러 메타데이터를 관리한다.)
카프카 프로듀서와 컨슈머에 대한 간단한 설명
코드를 이해하기 위해 간단한 동작 원리를 알아보자.
Producer
위에 설명했듯이, 프로듀서는 카프카로 이벤트를 퍼블리시한다.
이때 프로듀서가 발행한 이벤트는 key 와 파티션 개수에 따라 다르게 카프카에 적재된다.
1. key 가 null 이고,토픽의 파티션이 1개인 경우
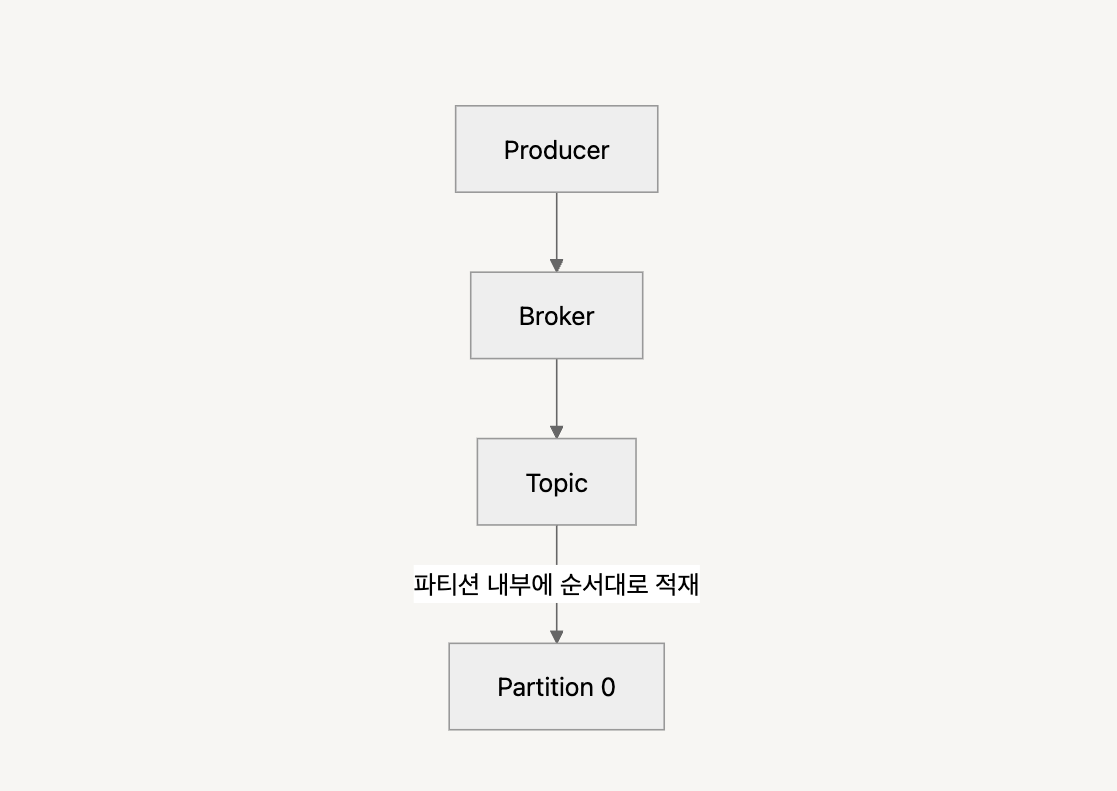
이 경우, 파티션에 메시지가 발행 된 순서대로 적재된다.
2. key 가 null 이고,토픽의 파티션이 여러개인 경우

이런 경우, 프로듀서가 발행한 메시지는 라운드로빈으로 각 파티션에 순서대로 들어가게 된다.
2. key 가 있고 파티션이 여러개인 경우

키가 있는 경우는 좀 다르게 동작한다.
프로듀서가 메시지와 함께 key를 보낸다.
그럼 해시 함수가 key의 해시 값을 계산한다.
이때 파티셔너는 해시 값을 기반으로 파티션을 선택한다.
-> 즉, 동일한 키로 메시지를 발행하면, 항상 같은 파티션에 들어간다는 뜻이다! (물론 순서가 보장된다.)
Consumer
컨슈머는 프로듀서가 카프카로 발행한 메시지를 소비하는 주체이다.
위 설명에 적진 않았지만, 카프카는 파티션에 적재된 메시지에 번호를 매긴다.
이를 offset 이라고 하는데, 들어온 순서를 나타낸다.

위 그림처럼 메시지에 들어온 순서대로 offset이 매겨진다.
컨슈머는 메시지를 소비하면, offset을 commit 한다.(자신이 마지막으로 어디까지 읽었는지를 기록한다!)
이를 기반으로 내가 메시지를 어디까지 읽었는지 파악하게 된다.
(이 기능이 있기에 중간에 모종의 이유로 서버가 죽더라도, 카프카 메시지를 어디까지 읽었는지 알 수 있고, 장애 복구가 쉬워진다!)
컨슈머와 프로듀서, 카프카에 대해선 매우 많은 내용이 존재한다.
설명에 적진 않았지만, 토픽에 대한 자세한 설명, 파티셔너 등 알아야 할 내용이 많지만, 여기에 다 정리하는 것은 불가능 하기에 참고한 내용들을 첨부하겠다.
https://devocean.sk.com/community/detail.do?ID=165478&boardType=DEVOCEAN_STUDY&page=1
[Kafka KRU] Consumer 내부 동작 원리와 구현
devocean.sk.com
https://bbejeck.medium.com/a-critical-detail-about-kafka-partitioners-8e17dfd45a7
A Critical Detail about Kafka Partitioners
Apache Kafka® is the de facto standard for event streaming today. Part of what makes Kafka so successful is its ability to handle…
bbejeck.medium.com
Kafka의 Sticky Partitioner 살펴보기
Kafka Broker(server)에 메시지를 주고받는 client 역할을 하는 Kafka Producer / Consumer 중 Producer의 성능 개선 기능이 있어 살펴보려고 한다. ref url: KIP-480, Apache Kafka Producer improvements Sticky Partitioner[Confluent Blo
dol9.tistory.com
구현
(전체 코드는 https://github.com/KUSITMS-31th-Seoul-Milk-team2/backend/tree/dev/src/main/java/com/seoulmilk/core/configuration/kafka 에서 볼 수 있다.)
카프카 Producer 설정
@Bean
public ProducerFactory<String, List<OcrValidationRequest>> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS); // 카프카 브로커의 주소를 설정한다.
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 브로커로 메시지를 보낼 때 메시지 키를 직렬화 할 방식을 설정한다.
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); // 브로커로 메시지를 보낼 때 메시지를 직렬화 할 방식을 정한다.
config.put(JsonSerializer.ADD_TYPE_INFO_HEADERS, true); // JSON 직렬화 시 타입 정보를 헤더에 추가한다. 이를 통해 역직렬화시 정확한 타입 복원에 도움을 줄 수 있다.
return new DefaultKafkaProducerFactory<>(config);
}
매우 간단하게 설정을 끝낼 수 있다.
프로듀서는 카프카의 토픽을 정하고 해당 토픽으로 메시지를 발행한다.
그러므로! 토픽 설정을 해보자.
카프카 Topic 설정
@Configuration
@RequiredArgsConstructor
public class KafkaTopicConfiguration {
private final KafkaProperties kafkaProperties;
@Bean
public NewTopic ocrResultTopic() {
return TopicBuilder.name(kafkaProperties.getTopic()) // 토픽 이름을 설정한다.
.partitions(kafkaProperties.getPartitionCount()) // 파티션의 개수를 설정한다.
.replicas(kafkaProperties.getReplicaCount()) // 레플리카의 개수를 설정한다.
.build();
}
}여기서 레플리카라는 개념이 나왔다.
이는 브로커의 복제본인데, 토픽은 여러개의 브로커 복제본을 가질 수 있다.
이때 메인으로 데이터를 처리하는 브로커를 Leader Partition , 나머지 복제본을 Follower Partition 이라 부른다.
이를 통해 Leader Partition 이 모종의 이유로 죽은 경우, Follower에서 새로운 Leader를 선출해 Fault Tolerent를 보장한다.
카프카 Consumer 설정
@Bean
public ConsumerFactory<String, Object> consumerFactory() {
Map<String, Object> configMap = new HashMap<>();
configMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS); // 카프카 브로커 주소를 설정한다.
configMap.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID); // 컨슈머 그룹 ID를 설정한다. 여러 컨슈머를 그룹으로 관리하는데 사용한다.
configMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 메시지 키의 역직렬화 방식을 설정한다.
configMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class); // 메시지 값의 역직렬화 방식을 설정한다.
configMap.put(JsonDeserializer.TRUSTED_PACKAGES, TRUSTED_PACKAGES); // 역직렬화 시 신뢰할 수 있는 패키지를 설정한다. 이는 특정 패키지의 클래스만 역직렬화하겠다~ 란 의미다.
return new DefaultKafkaConsumerFactory<>(configMap);
}
이렇게 설정을 마쳤다!
우리는 OCR 추출에서 국세청 검증 이 과정을 이벤트 기반으로 처리하려 했기에 해당 플로우를 구현해보자!
이벤트 발행하기
아래 코드는 Kafka로 이벤트를 발행하는 코드이다!
@Component
@RequiredArgsConstructor
public class KafkaOcrEventPublisher implements OcrEventPublisher {
private final KafkaTemplate<String, List<OcrValidationRequest>> kafkaTemplate;
private final KafkaProperties kafkaProperties;
@Override
public void publish(List<OcrValidationRequest> event) {
kafkaTemplate.send(kafkaProperties.getTopic(), event);
}
}
이제 발행해보자!
@RestController
@RequiredArgsConstructor
@RequestMapping("/v1/invoice")
public class InvoiceOcrController implements InvoiceOcrSwagger {
private final OpenFeignService openFeignService;
private final OcrEventPublisher ocrEventPublisher;
@PostMapping
public ResponseEntity<RestResponse<Boolean>> uploadMultipleFiles(
@AuthenticationPrincipal CustomUserDetails customUserDetails,
@RequestPart("files") List<MultipartFile> files) {
// 1. OCR 값 추출
List<OcrValidationRequest> results = files.stream()
.map(...)
.toList();
// 2. Event로 발행
CompletableFuture.runAsync(() -> {
List<OcrValidationRequest> validResults = results.stream()
.filter(result -> result != null)
.toList();
log.info("validResults: {}", validResults);
ocrEventPublisher.publish(validResults);
});
return ResponseEntity.ok(new RestResponse<>(true));
}
}위 컨트롤러를 간단히 설명하면
1. 유저에게 받은 파일의 Text를 Naver OCR을 통해 추출한다.
2. 해당 추출한 Text를 Event로 발행한다.
이벤트 소비하기
소비는 훨씬 간단하다.
@Service
@RequiredArgsConstructor
@Log4j2
public class TaxReceiptValidationService {
@KafkaListener(topics = "${kafka.topic}", groupId = "${kafka.group-id}")
public void listen(List<OcrValidationRequest> ocrValidationRequestList) {
...
}
}
기본적으로 위와 같은 구성이다.
어떤 토픽을 구독할지, 어떤 컨슈머 그룹에 속해있는지를 설정해주면 끝이다!
이렇게 이벤트 기반 파이브라인을 구성할 수 있었다.
트러블 슈팅
사실 위에 설명한 설정을 적용하면 에러가 많이 발생한다 ㅎㅎ..
이 플로우를 구성하기 위해 겪었던 트러블 슈팅에 대해 정리해보려 한다!
1. 컨슈머 역직렬화
먼저 Consumer 에서 이벤트를 받지 못하는 상황이 발생했다.

내가 보내는 데이터 타입은 List<OcrValidationRequest> 타입이었는데,
서버에선 빈 배열로 받고 있었다.
아래는 Consumer 설정이다.
@Bean
public ConsumerFactory<String, Object> consumerFactory() {
Map<String, Object> configMap = new HashMap<>();
configMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS); // 카프카 브로커 주소를 설정한다.
configMap.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID); // 컨슈머 그룹 ID를 설정한다. 여러 컨슈머를 그룹으로 관리하는데 사용한다.
configMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 메시지 키의 역직렬화 방식을 설정한다.
configMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class); // 메시지 값의 역직렬화 방식을 설정한다.
configMap.put(JsonDeserializer.TRUSTED_PACKAGES, TRUSTED_PACKAGES); // 역직렬화 시 신뢰할 수 있는 패키지를 설정한다. 이는 특정 패키지의 클래스만 역직렬화하겠다~ 란 의미다.
return new DefaultKafkaConsumerFactory<>(configMap);
}
원인을 생각해보니 2가지로 좁혀졌다.
1. OcrValidationRequest 클래스 패키지가 TrustedPackage에 없는 경우
consumer:
group-id: ocr-group
auto-offset-reset: earliest
value-deserializer: "com.seoulmilk.core.configuration.kafka.deserializer.OcrValidationRequestListDeserializer"
properties:
spring.json.add-type-headers: true
spring.json.trusted.packages: "com.seoulmilk.receipt.dto.request"위와 같이 truested.packages 에 추가를 해줬지만, 역직렬화에 실패했다.
2.JsonDeserializer 가 제네릭 컬렉션 타입을 제대로 인식하지 못하는 경우
JsonDeserializer가 제네릭 컬렉션 타입을 인식하지 못해서 생기는 문제임을 알고, 커스텀 역직렬화 코드를 작성했다.
package com.seoulmilk.core.configuration.kafka.deserializer;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.core.JsonToken;
import com.fasterxml.jackson.databind.DeserializationContext;
import com.fasterxml.jackson.databind.JavaType;
import com.fasterxml.jackson.databind.deser.std.StdDeserializer;
import com.seoulmilk.receipt.dto.request.OcrValidationRequest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class OcrValidationRequestListDeserializer extends StdDeserializer<List<OcrValidationRequest>> {
public OcrValidationRequestListDeserializer() {
this(null);
}
public OcrValidationRequestListDeserializer(Class<?> vc) {
super(vc);
}
@Override
public List<OcrValidationRequest> deserialize(JsonParser p, DeserializationContext ctxt) throws IOException {
List<OcrValidationRequest> result = new ArrayList<>();
if (p.currentToken() == JsonToken.START_ARRAY) {
p.nextToken();
if (p.currentToken() == JsonToken.START_ARRAY) {
while (p.nextToken() != JsonToken.END_ARRAY) {
result.add(deserializeSingleRequest(p, ctxt));
}
p.nextToken();
}
else {
while (p.currentToken() != JsonToken.END_ARRAY) {
result.add(deserializeSingleRequest(p, ctxt));
p.nextToken();
}
}
}
else if (p.currentToken() == JsonToken.START_OBJECT) {
result.add(deserializeSingleRequest(p, ctxt));
}
return result;
}
private OcrValidationRequest deserializeSingleRequest(JsonParser p, DeserializationContext ctxt) throws IOException {
JavaType type = ctxt.getTypeFactory().constructType(OcrValidationRequest.class);
return ctxt.readValue(p, type);
}
}
위 커스텀 직렬화 코드를 자세히 살펴보자.
if (p.currentToken() == JsonToken.START_ARRAY) { // 배열 감지
p.nextToken();
if (p.currentToken() == JsonToken.START_ARRAY) { // 2차원 배열 감지
while (p.nextToken() != JsonToken.END_ARRAY) {
result.add(deserializeSingleRequest(p, ctxt));
}
p.nextToken(); // 리스트 요소 간 토큰 이동
}
else { // 1차원 배열인 경우
while (p.currentToken() != JsonToken.END_ARRAY) {
result.add(deserializeSingleRequest(p, ctxt));
p.nextToken();
}
}
}2차원 배열 파싱도 구현한 이유
처음에 ConcurrentKafkaListenerContainerFactory의 BatchListener 타입을 true 로 설정했다.
이렇게 설정하면 Kafka 컨슈머가 poll() 한 전체 레코드 배치를 리스너 메서드에 전달하게 된다.
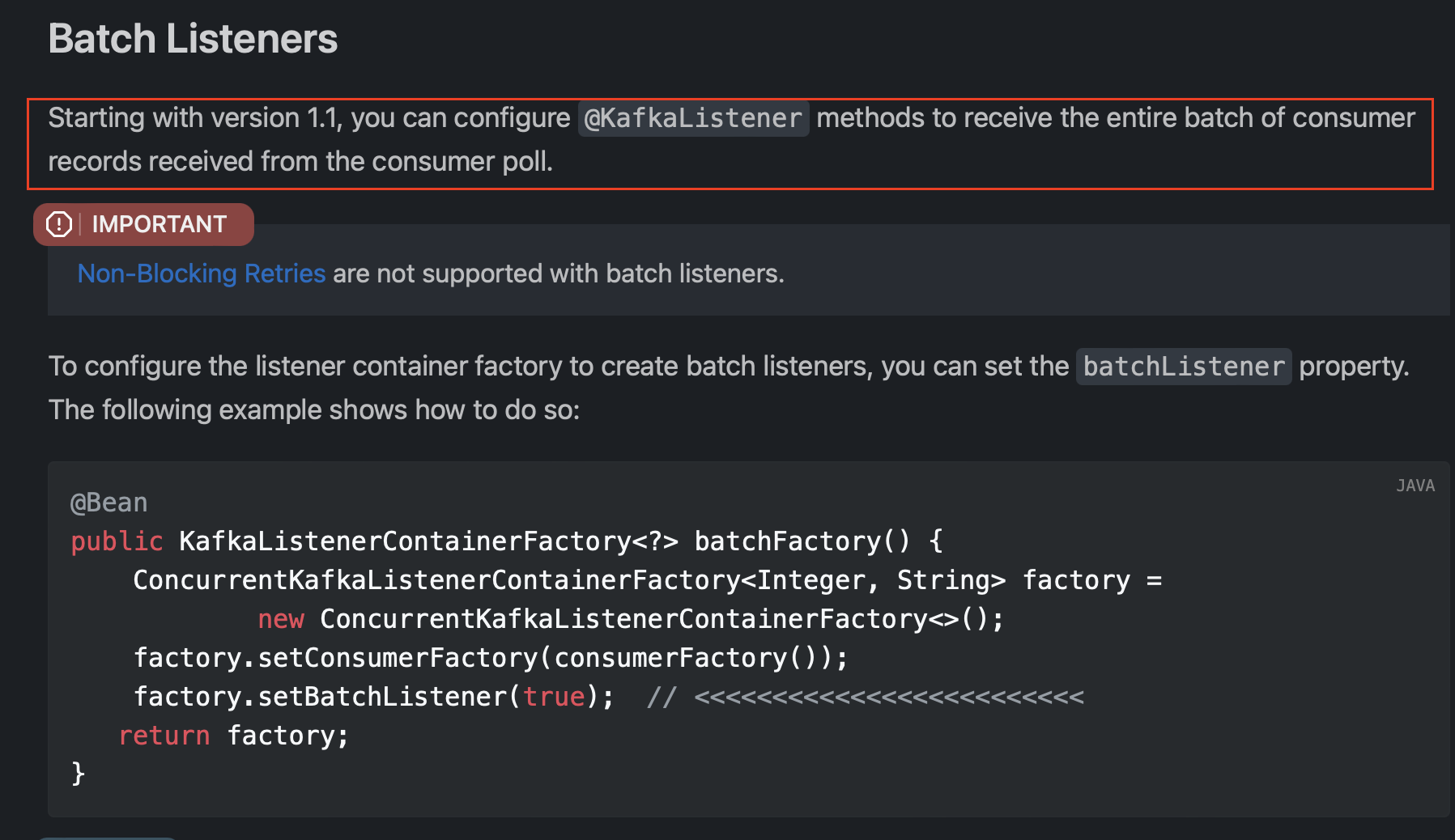
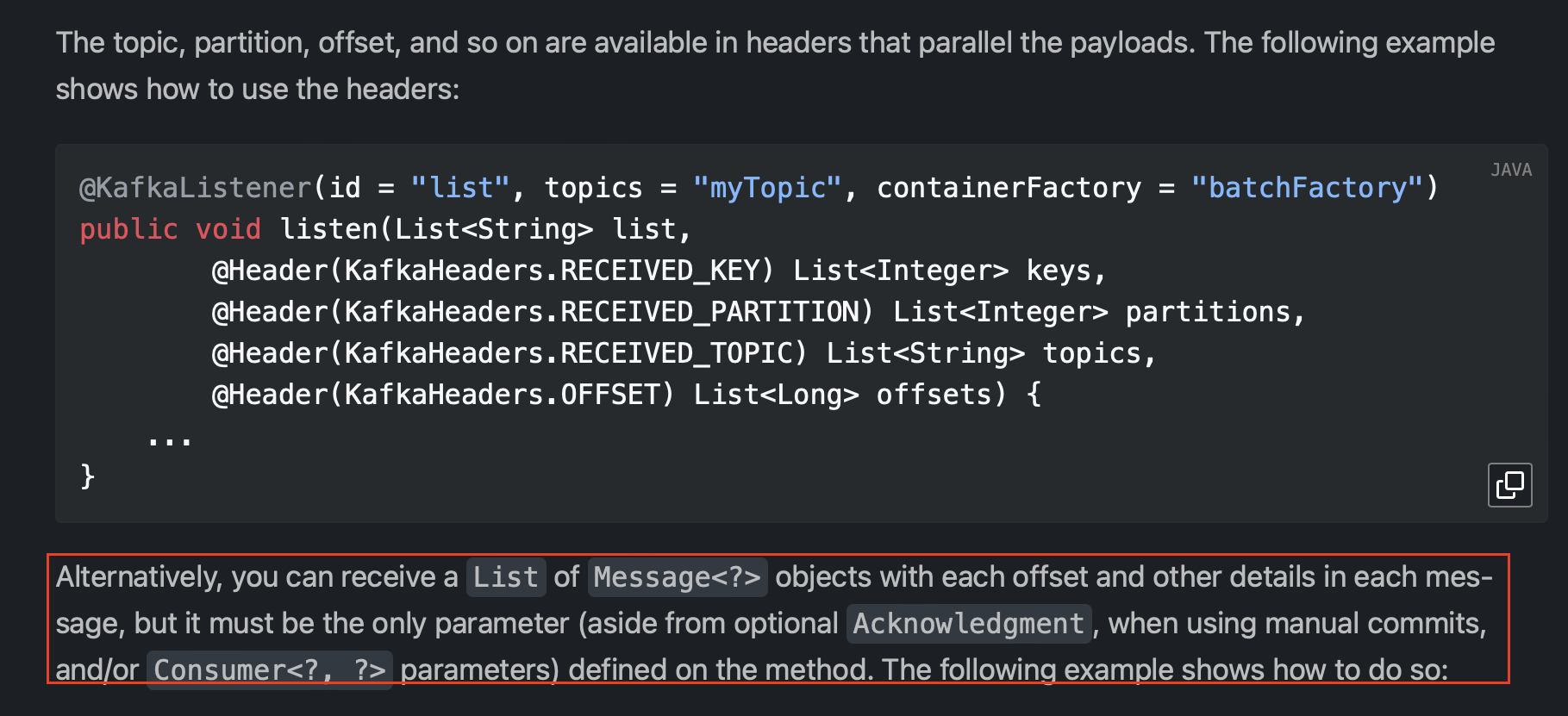
컨슈머의 poll() 작업으로 모은 여러 메시지가 단일 리스트로 반환된다는 뜻이다.
처음 직렬화 코드를 구현할 땐 , BatchListener 를 true 로 설정한 것을 잊고 있어 2차원 배열과 1차원 배열 파싱 둘 다 구현했다.
아래는 단일 객체로 들어왔을 경우, 해당 객체를 역직렬화하기 위한 코드이다.
else { // 단일 객체 처리
while (p.currentToken() != JsonToken.END_ARRAY) {
result.add(deserializeSingleRequest(p, ctxt));
p.nextToken();
}
}
현재 전달하는 이벤트의 타입이 OcrValidationRequest 의 배열이므로, 단일 객체의 역직렬화를 위해 OcrValidationRequest 타입 역직렬화 메서드를 사용했다.
private OcrValidationRequest deserializeSingleRequest(...) {
JavaType type = ctxt.getTypeFactory().constructType(OcrValidationRequest.class);
return ctxt.readValue(p, type);
}
위와 같이 커스텀 역직렬화를 구현하고 나니 , 컨슈머에서 제대로 이벤트를 받을 수 있었다!
2. 카프카 에러 핸들링
OCR 값을 변환해 국세청 검증을 할 때 카카오 인증이 10번 오는 경우가 있었다.
(카프카를 공부한 적 있는 사람이라면 눈치를 챘을 것이다.)
프로듀서가 보내는 이벤트는 List<OcrValidationRequest> 형태였다.
먼저 의심했던 부분은 다음과 같다.
1. List의 원소 개수 만큼 인증이 찍히는 것인가?
Codef로 요청 보내는 로직을 살펴보았다.
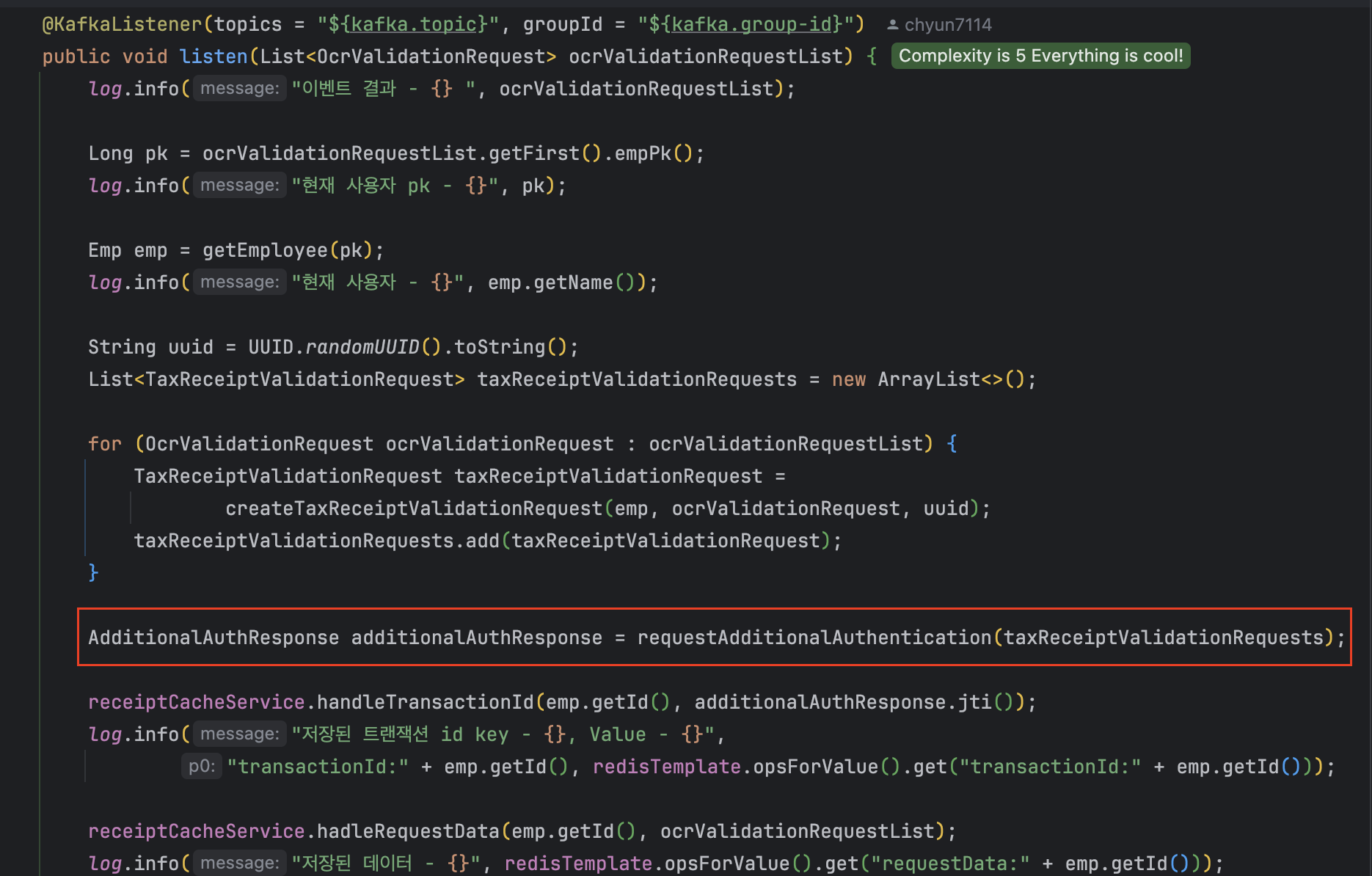
AdditionalAuthResponse 가 인증 결과이다.
해당 값을 얻기 위해 requestAdditionalAuthentication 으로, 추출한 세금 계산서 값을 보낸다.


EasyCodef가 제공하는 다건인증의 경우, List<>로 요청을 보내야 한다.
아무리 봐도 에러가 여러번 찍힐 이유가 없었다.
디버거를 돌려봐도 Codef API 로 여러번 요청을 보내는 로직이 없었다.
그래서 혹시 에러의 원인이 Codef 가 아닌가? 라는 생각이 들었다.
2. Codef가 아닌 다른 곳에 원인이 있다.
Codef API가 원인이 아닐 수 있기에, 인증 API를 주석처리하고, 에러를 발생시켜 보았다.
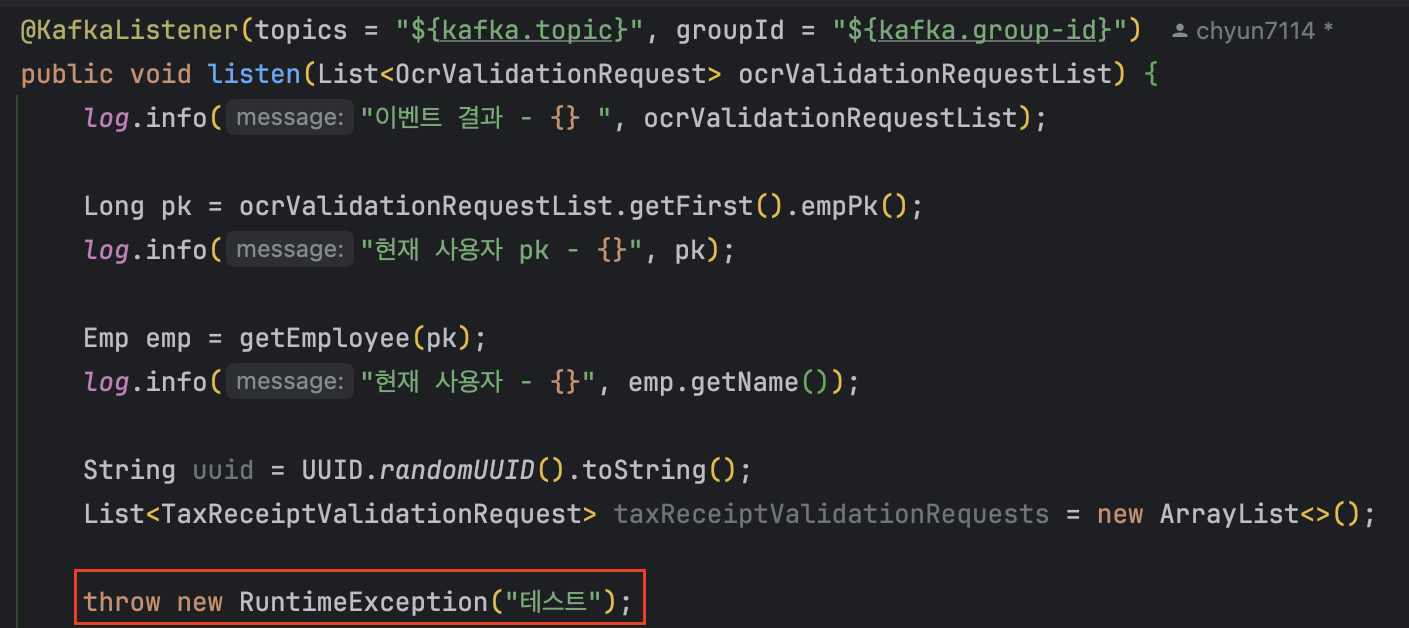
일반 에러도 10번 발생을 하는 것을 보았다.
그리고 에러 로그를 자세히 살펴보니 DefaultErrorHandler의 기본 동작이 10회 재시도라는 것을 알았다.


카프카는 에러 발생시 10번 재시도를 한다.
에러 발생시 재시도를 안하려 NoRetryErrorHandler 를 구현했다.


에러 발생 시 재시도를 삭제하니 로직이 제대로 동작했다!
* 당시엔 구현에 급급했다. 현재 다시 찾아보니 KafkaDefaultErrorHandler 의 재시도 횟수를 0으로 조절하고, 에러 발생시 다른 로직을 실행시킬 수 있음을 알았다. 이 부분은 추후 리팩토링 할 예정! (리팩토링이 완료되면 이 글에 추가하겠다.)
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
결론
카프카를 처음 사용하다 보니, 에러도 많았고, 구현에 급급한 것이 대부분이었다.
잘못된 코드들을 리팩토링 해야 할 필요가 있다.