
서울우유와 함께 한 기업프로젝트가 끝났다.
구현이 끝났으니, 성능을 측정해보고 개선을 해보자!
개선을 해볼 API는 공지사항 조회이다.
아무래도 모든 유저가 접근할 수 있는 API이기도 하고, 읽기 작업이 주를 이루는 API이므로 선택했다.
성능 비교
성능을 개선하기 전에 어떤 지점에서 조회 성능이 떨어지는지를 확인해보자!

서울우유 측에서 받은 정보이다.
관련 업무를 처리하는 인원이 50명이므로, 테스트 시 인원 수 Max를 50으로 맞췄다.
1 페이지에만 접근하기
모든 유저가 공지사항 페이지에 접근하면 첫 번째 페이지로 접근한다.
page == 1 인 API에 대해 성능을 체크해보자.
request 성공 여부 고려
11000 건 데이터

1000000건 데이터((백만건)

10000000건 데이터 (천만건)

request 성공 여부 + 응답 시간을 함께 고려

구글에선 응답 시간을 0.5초 미만으로 줄이는 것이 목표이다.
이를 따라 우리 API 의 응답 기준도 0.5초로 맞추고 테스트를 진행해보았다.
1000000건 데이터(백만건)
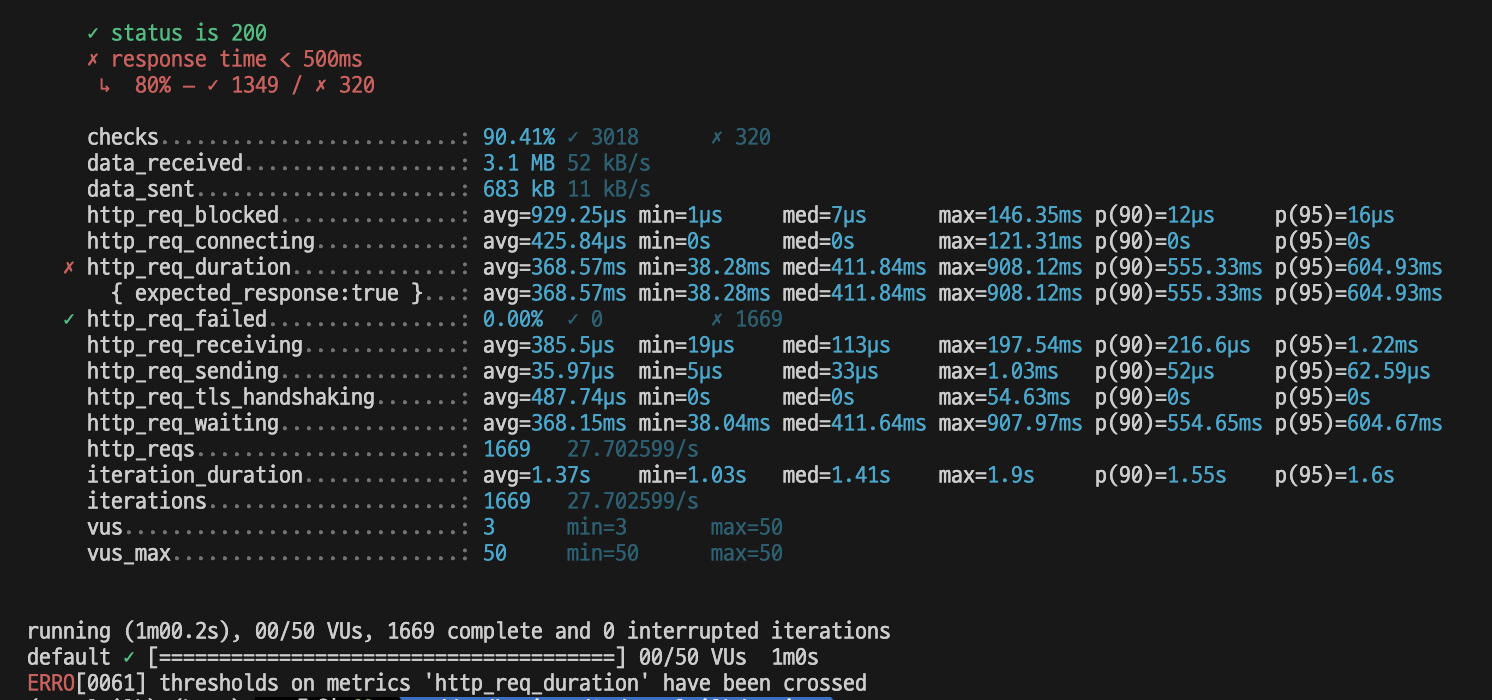
백만건의 데이터를 넘어가자 응답시간이 0.5초를 초과하는 데이터가 나오기 시작했다.
10000000건 데이터 (천만건)

2번의 요청을 제외하고, 전부 0.5초 이상 걸렸다.
http_req_duration 을 보면 첫 페이지에 접근하는데 평균 9.62초가 걸렸다.
이제 개선을 해보자!
불필요한 정렬 제거

API 요청을 보낼 때 JPA 쿼리이다.
현재 정렬을 중복으로 2번 하고 있는데, 이 부분을 1번으로 줄이면 조금의 개선을 얻을 수 있어 보인다.
Pageable 을 인자로 넘겨주면 기본적으로 내림차순 정렬을 한다.
하지만 난 그 사실을 모르고, @Query에서 한 번 더 정렬을 했다.
@Query("SELECT n FROM NoticeJpaEntity n ORDER BY n.id DESC")
Page<NoticeJpaEntity> findAllOrderByIdDesc(Pageable pageable);
위 코드의
@Query("SELECT n FROM NoticeJpaEntity n")
Page<NoticeJpaEntity> findAllOrderByIdDesc(Pageable pageable);정렬을 없애주니, 정렬이 한 번만 나갔다!

페이지네이션 부분의 실행계획을 분석해보자.
페이지네이션과 실행계획 분석
EXPLAIN PLAN FOR
select
nje1_0.id,
nje1_0.author_name,
nje1_0.author_pk,
nje1_0.content,
nje1_0.created_at,
nje1_0.deleted,
nje1_0.file_url,
nje1_0.title,
nje1_0.updated_at
from
notice nje1_0
order by
nje1_0.id desc
fetch
first :take rows only;
현재 NOTICE 에 대한 풀 스캔을 하고 있다.
아무 인덱스가 걸려있지 않기에, 페이지네이션을 커스텀해보고, 인덱스를 사용해 성능을 개선해보려 한다.
페이지네이션 커스텀
현재 우리 조회 코드에선 Pageable 을 사용한다.
Pageable 을 사용하면, DB의 limit 과 Offset 쿼리를 통해 '페이지' 단위로 데이터를 구분한다.
페이징을 구현하기 위해 '전체 데이터 개수' 를 가져와 전체 페이지 개수를 계산하고, 현재 페이지가 첫 번째인지, 마지막 페이지인지 계산해야한다.
이런 과정으로 인해 쿼리가 2회 나간다. (데이터 요청, 데이터 개수 카운트)
이는 페이지가 뒤로 갈 수록 읽고, 계산해야 할 양이 많아지기에 성능이 저하된다.
랜덤하게 조회 요청을 보냈을 때 Timeout이 온 것을 보면 알 수 있다.

쿼리를 보고도 알 수 있다.
이를 해결하기 위해 페이지네이션을 커스텀 해보았다.
EXPLAIN PLAN FOR
SELECT
n.id,
n.author_name,
n.title,
n.created_at
FROM notice n
ORDER BY n.id DESC
OFFSET :skip ROWS FETCH NEXT :take ROWS ONLY;
페이지네이션 코드의 실행계획을 분석해보자.
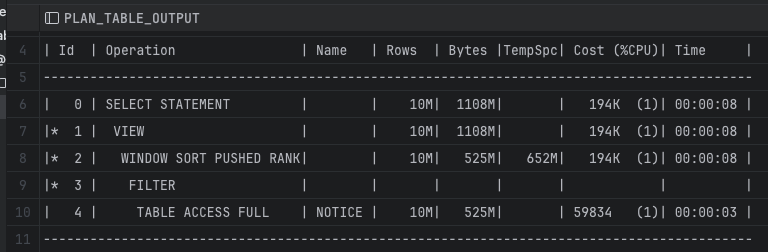
현재 풀스캔을 하고 있다.
이를 인덱스를 통해 수정해보려 했다.
페이지 기반 페이지네이션의 경우 OFFSET을 사용한다. 이는 테이블을 풀 스캔 한다.
어떤 인덱스를 둬도, 테이블을 풀 스캔하기에 우리가 필요한 값만 커버링 인덱스를 만들어 사용해보자.
EXPLAIN PLAN FOR
SELECT /*+ INDEX_DESC(n idx_notice_covering) */
n.id,
n.author_pk,
n.author_name,
n.title,
n.content,
n.file_url,
n.created_at,
n.updated_at,
n.deleted
FROM notice n
ORDER BY n.id DESC
OFFSET :skip ROWS FETCH NEXT :take ROWS ONLY;
여기서 문제는 content가 CLOB 타입이란 점이다.
CLOB은 인덱스에 포함될 수 없다.
그 외에 여러 인덱스를 걸어보았지만, 성능이 더 나아지는 경우가 없었다.
성능 개선을 하기위해선 불필요한 ORDER를 없애거나, 인덱스를 적용해야 한다.
그러나 페이지 기반 페이지네이션을 사용하게 되면, OFFSET을 쓸 수 밖에 없다.
OFFSET의 특성 상 풀 스캔을 할 수 밖에 없고, 페이지 기반 페이지네이션의 경우 어디에 인덱스를 걸어야 하는지도 명확하지 않았다.
그래서 인덱스와 커스텀 페이지네이션을 사용하기보다, Pageable 객체를 사용하고 캐싱을 통해 성능을 개선하는 방법을 선택했다.
만약 커서 기반 페이지네이션을 사용한다면?
현재 우리 조회 코드에선 Pageable 을 사용한다.
Pageable 을 사용하면, DB의 limit 과 Offset 쿼리를 통해 '페이지' 단위로 데이터를 구분한다.
페이징을 구현하기 위해 '전체 데이터 개수' 를 가져와 전체 페이지 개수를 계산하고, 현재 페이지가 첫 번째인지, 마지막 페이지인지 계산해야한다.
이런 과정으로 인해 쿼리가 2회 나간다. (데이터 요청, 데이터 개수 카운트)
이는 페이지가 뒤로 갈 수록 읽고, 계산해야 할 양이 많아지기에 성능이 저하된다.
이를 해결하기 위해 커서 기반 페이지네이션으로 변경했다.

쿼리가 더 간결해진 것을 볼 수 있다.
쿼리의 실행계획을 분석해보자!

현재 INDEX가 걸려있지 않아 , 풀 테이블 스캔을 하고 있다(3).
그리고 추가적인 정렬 작업이 발생한다(2).
이를 해결하기 위해 인덱스를 적용해보자!
CREATE INDEX idx_notice_id ON notice (id DESC);

성능이 조금 좋아지긴 했지만, 아직도 불필요한 정렬 작업을 수행하고 있다.(SORT ORDER BY)
내가 id DESC 로 인덱스를 생성했다.
여기서 DESC 내림차순 인덱스를 생성하면 내부적으로 함수 기반 인덱스로 처리된다.
기본적으로 인덱스는 함수 결과값으로 정렬되어 있다.
그러므로 SORT ORDER BY 가 먼저 실행이 된다. <- 여기서 불필요한 정렬이 발생한다.
이를 해결하기 위해 기본 id 인덱스(오름차순)으로 정렬하고, 힌트를 사용했다.
CREATE INDEX idx_notice_id ON notice (id);EXPLAIN PLAN FOR
SELECT /*+ INDEX_RC_DESC(n idx_notice_id) */
n.id,
n.author_pk,
n.author_name,
n.title,
n.content,
n.file_url,
n.created_at,
n.updated_at,
n.deleted
FROM notice n
WHERE n.id < :key
ORDER BY n.id DESC
FETCH FIRST :take ROWS ONLY;
실행계획을 보니
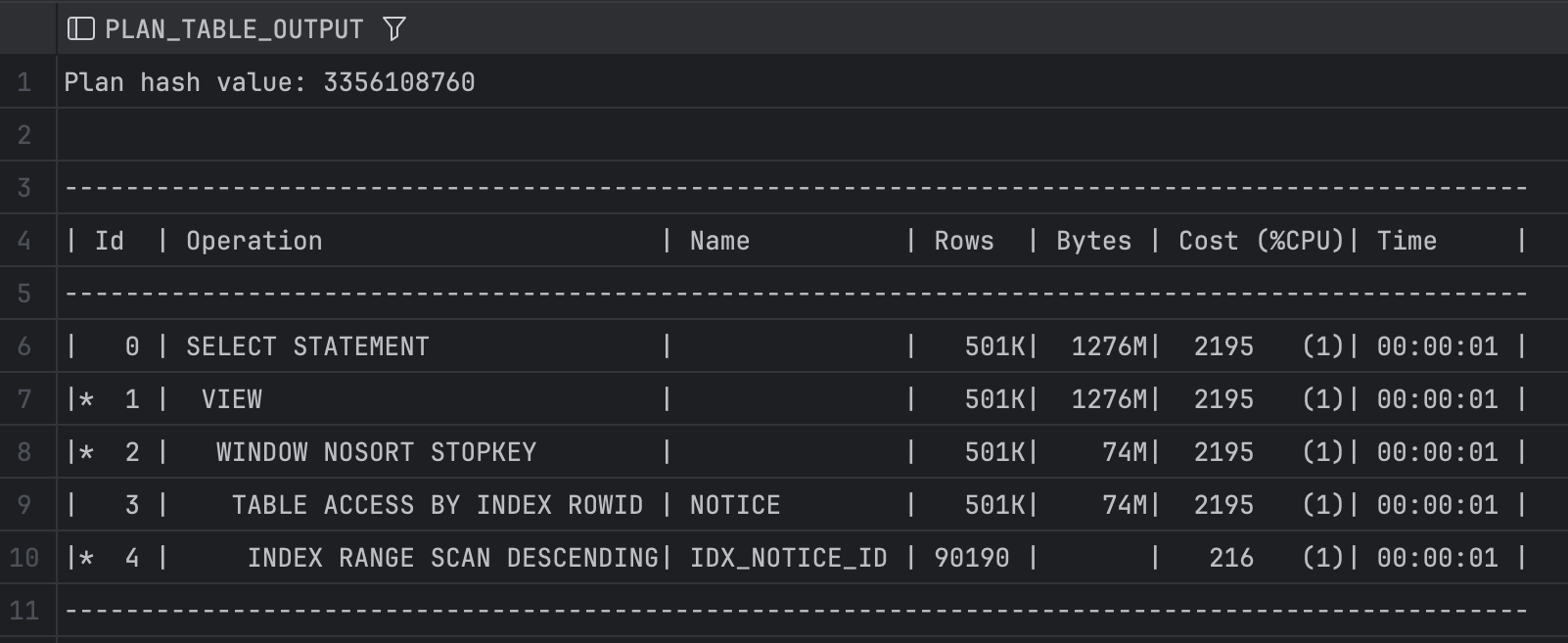
전체 코스트가 매우매우 줄어들었다!!
추가로 필요한 데이터만 반환하도록 쿼리를 수정한 뒤, 실행계획을 분석해보자.
EXPLAIN PLAN FOR
SELECT /*+ INDEX_RC_DESC(n idx_notice_id) */
n.id,
n.title,
n.author_name,
n.created_at
FROM notice n
WHERE n.id < :key
ORDER BY n.id DESC
FETCH FIRST :take ROWS ONLY;

사용하는 공간(Bytes)도 줄어들었다!
레포지토리 쿼리도 인덱스를 사용하도록 변경했다.
@Query(value = """
SELECT /*+ INDEX_RS_DESC(n idx_notice_id) */
n.id,
n.title,
n.author_name,
n.created_at,
FROM notice n
WHERE n.id < ?1
ORDER BY n.id DESC
FETCH FIRST ?2 ROWS ONLY
""", nativeQuery = true)
List<NoticeJpaEntity> findAllByPaginationDesc(Long key, Long take);
다시 k6로 테스트를 돌려보았다.
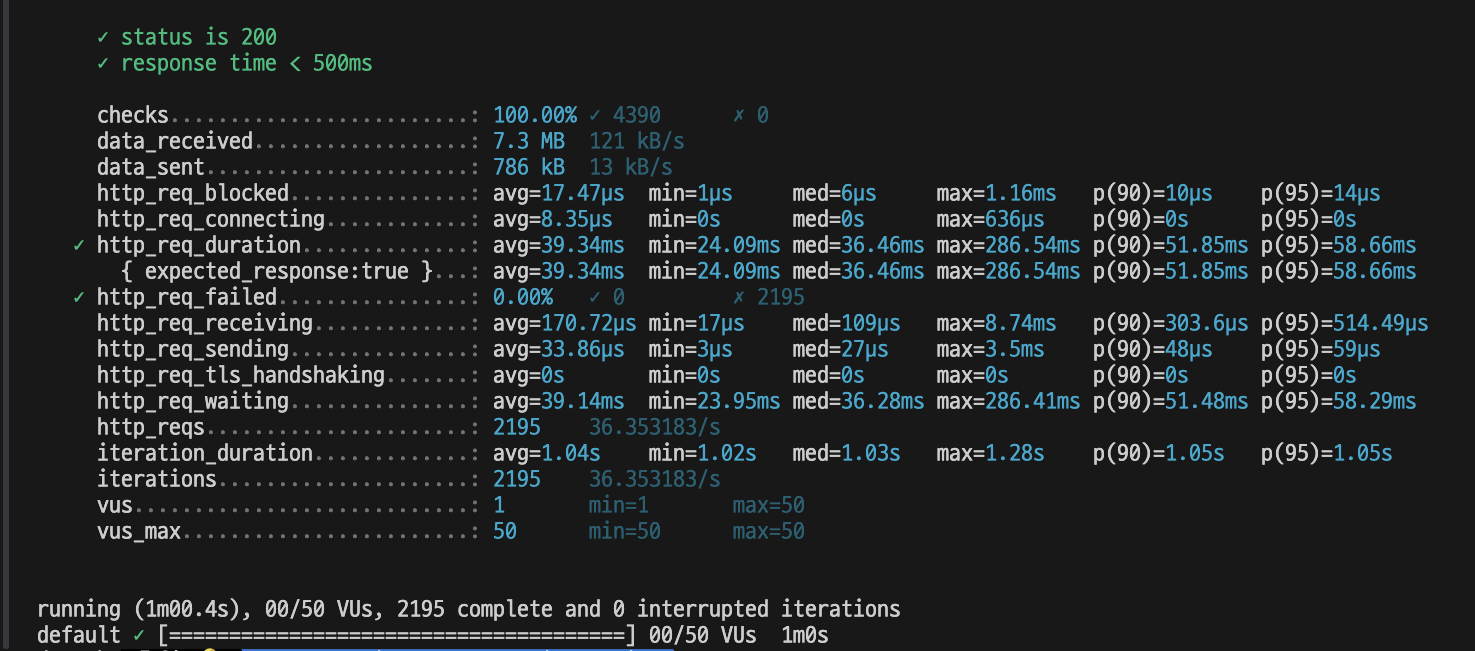
천만건의 데이터에서 1페이지의 경우, 모든 요청이 500ms 안으로 들어왔다!
천만건의 데이터에서 랜덤하게 요청을 보내보자.
커서 기반 페이지네이션엔 페이지가 없기에 , 임의로 몇 개의 랜덤 url을 선정해 요청을 보냈다.
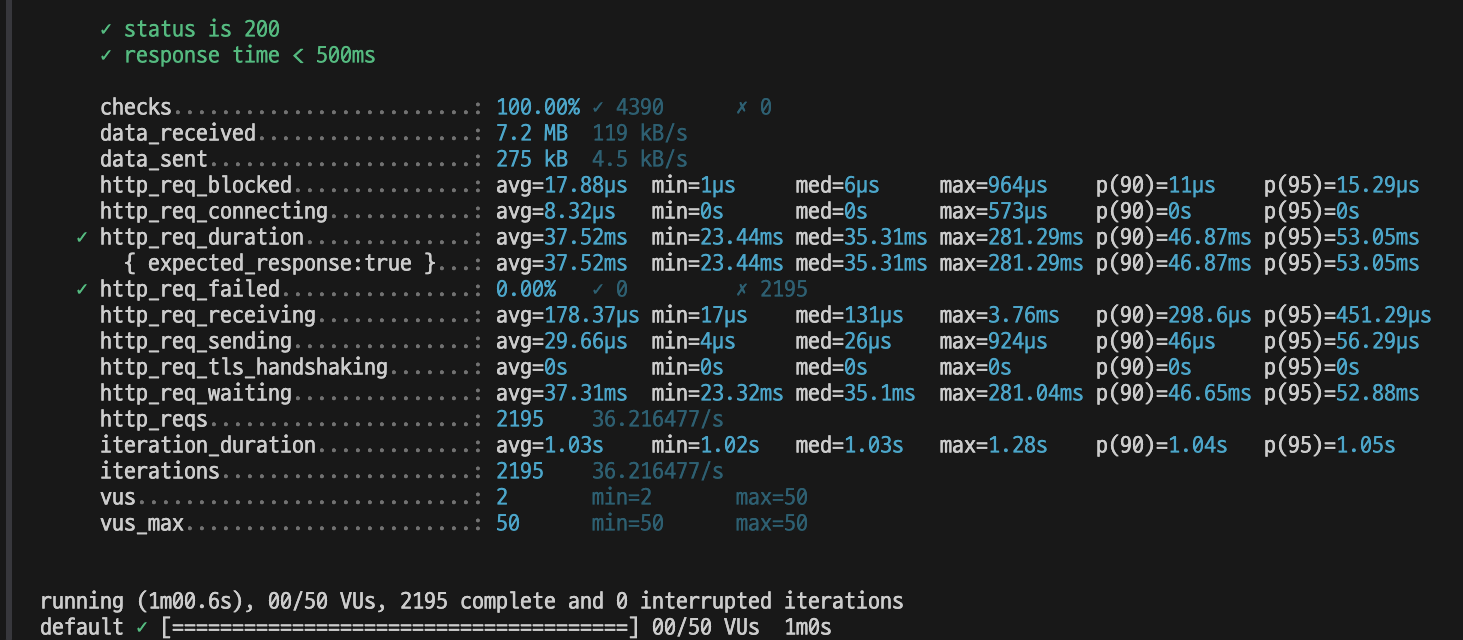
모든 요청이 500ms 안으로 들어왔다!
캐시
더 빠른 조회를 위해 캐싱을 사용해보자!
인덱스를 사용했지만 유의미한 결과를 얻지 못했다.
캐시를 사용하면 더욱 빨라질 것이라 생각해 캐시도 적용해보기로 했다.
먼저 캐시를 사용함에 있어 2가지 선택지를 고민했다.
일반적으로 대규모 회사나 MSA 환경에선 여러 서비스가 분리되어 돌아간다.
이런 경우 로컬 캐시를 사용하게 되면, 캐시 간의 정합성이 깨진다.
서버 간 데이터 공유가 안되기에 캐싱된 데이터에 따라 서버 간 데이터 불일치가 발생한다.
그러다보니 Redis와 같은 글로벌 캐시를 사용하게 된다.
글로벌 캐시를 사용하게 되면, 서버 간 데이터 공유가 가능하다.
여러 클라이언트가 같은 데이터를 바라보게 된다.
그럼에도 로컬 캐시가 가지는 장점은 확실하다.
- 조회를 위해 네트워크를 트래픽으로 사용하지 않는다.
- 외부 서비스를 사용하지 않기에 지연 의존이 떨어진다.
- 서버 리소스 효율성이 올라가 서버 성능이 개선된다.
그러나 현재 우리의 시스템은 모놀리틱의 형태이다.
서울우유의 경우 MSA 환경을 사용할 가능성이 높다고 생각했다.
그러기에 로컬 캐시와 글로벌 캐시를 둘 다 사용하기로 결정했다.
2계층 캐시
2계층 캐시는 동일한 요청에 대해 로컬 캐시를 조회하고 있으면 반환, 없다면 분산 캐시를 조회하여 그 결과를 반환하는 것이다.
2계층 캐시를 사용했을 때 장점은 글로벌 캐시(분산 캐시)로의 과도한 트래픽을 보호할 수 있다. 그리고 분산 캐시가 다운되더라도, 로컬 캐시를 사용할 수 있기에 서비스에 큰 문제를 막을 수 있다.
구현
분산 캐시로 Redis, 로컬 캐시로 Caffeine 을 사용하기로 결정했다.
@Bean
RedisCacheConfiguration redisCacheConfiguration(ObjectMapper objectMapper) {
return RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new Jackson2JsonRedisSerializer<>(objectMapper, PageNoticeResponse.class)
)).entryTtl(Duration.ofMinutes(10));
}
먼저 Redis 설정을 추가했다.
직렬화 설정을 추가해주고, 만료시간은 10분으로 줬다.
로컬 캐시에 대한 설정도 추가해줬다.
@Bean
public CacheManager customCacheManager(RedisConnectionFactory redisConnectionFactory, RedisCacheConfiguration redisCacheConfiguration) {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
caffeineCacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(Duration.ofMinutes(5)));
}
CacheManager 를 커스텀해 2계층 캐시를 구현한 뒤 , 이를 Configuration에 추가했다.
@Bean
public CacheManager customCacheManager(RedisConnectionFactory redisConnectionFactory, RedisCacheConfiguration redisCacheConfiguration) {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
caffeineCacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(Duration.ofMinutes(5)));
RedisCacheManager redisCacheManager = RedisCacheManager.builder(redisConnectionFactory)
.cacheDefaults(redisCacheConfiguration)
.build();
return new CustomCacheManager(caffeineCacheManager, redisCacheManager);
}
캐시에 저장할 때 2계층 캐시를 제대로 활용하기 위해 Cache 구현체를 만들어 주었다!
public record CustomCache(Cache firstLevelCache, Cache secondLevelCache) implements Cache {
...
@Override
public <T> T get(Object key, Class<T> type) {
T value = firstLevelCache.get(key, type);
if (value == null) {
value = secondLevelCache.get(key, type);
if (value != null) {
firstLevelCache.put(key, value);
}
}
return value;
}
@Override
public void put(Object key, Object value) {
firstLevelCache.put(key, value);
secondLevelCache.put(key, value);
}
...
}
현재 성능 개선의 목표인 페이지네이션 코드에 캐시를 적용해보자.
@Cacheable(
value = "notice",
cacheManager = "customCacheManager",
keyGenerator = "noticePageableKeyGenerator"
)
public PageNoticeResponse<NoticeSummaryResponse> getNoticesByPage(Pageable pageable) {
cacheService.checkCacheContent();
log.info("[ReadNoticeService.getNoticesByPage] 공지사항 페이지를 조회합니다.");
Page<Notice> notices = noticeRepository.findAllOrderByIdDesc(pageable);
List<NoticeSummaryResponse> content = notices.getContent().stream()
.map(NoticeSummaryResponse::create).toList();
return PageNoticeResponse.create(content, notices);
}read 요청이 들어 올 경우, 캐시를 읽도록 설정한다.
여기서 문제는 이렇다.
만약 공지사항에 새로운 공지를 추가하고, 캐시를 evict 하는 로직이다.
공지가 제대로 추가되면 좋지만, 모종의 이유로 공지 추가 도중 에러가 발생해 롤백이 될 수 있다.
이런 경우를 막기 위해 커밋 시 event를 발행하고 해당 event가 발행되면 캐시가 evict 되도록 했다.
@Transactional
public PostNoticeResponse post(CustomUserDetails customUserDetails, PostNoticeRequest postNoticeRequest, MultipartFile file) {
String fileUrl = fileUtil.uploadFile(file);
try {
Notice notice = noticeRepository.save(
Notice.create(customUserDetails.getId(), customUserDetails.getUsername(), postNoticeRequest.title(), postNoticeRequest.content(), fileUrl)
);
postNoticeEventPublisher.publishPostNoticeEvent();
return PostNoticeResponse.create(notice);
} catch (Exception e) {
log.error("[PostNoticeService.post] 공지사항을 등록하는데 실패했습니다. {}", e.getMessage());
throw NoticeErrorCode.POST_NOTICE_FAILED.toException();
}
}
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
@CacheEvict(
value = "notice",
cacheManager = "customCacheManager",
allEntries = true
)
public void evictNoticePageableCache(PostNoticeEvent postNoticeEvent) {
log.info("[PostNoticeService.evictNoticePageableCache] 공지사항 페이지 캐시를 삭제합니다.");
}
캐시를 구현했으니, 실제 성능을 테스트해보자.
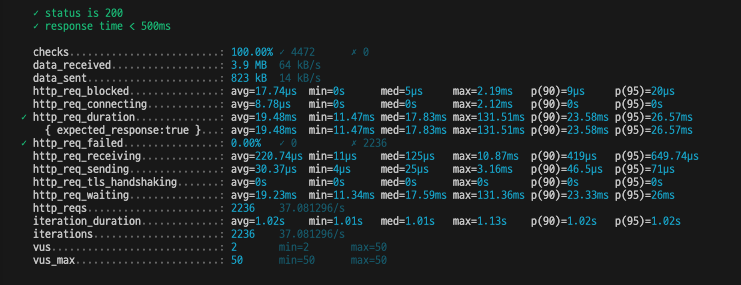
캐시를 적용한 뒤 1 페이지 조회 테스트를 진행하니 모두 성공했다!(1000만건)
평균 응답 시간 역시 0.02ms로 매우 빠르다.
이제 랜덤 페이지에 접근하는 경우도 테스트해보자.
1~20페이지에 랜덤하게 접근하는 경우를 테스트 해보았다.
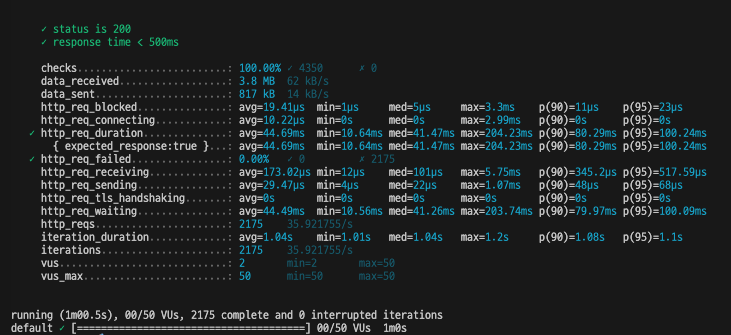

캐싱이 잘 되었고, 성능도 잘 나왔다!
처음엔 1페이지에 대한 천만건 데이터의 평균 응답이 9.62초였다.
캐시를 적용한 뒤 천만건 데이터의 평균 응답이 19 밀리초로 줄었다!
성능 개선율을 다음과 같이 계산해보았다.
개선율 = ((초기 응답 시간 - 개선된 응답 시간) / 초기 응답 시간 ) * 100
-> (9.62 s - 19 ms / 9.62s) * 100
이를 통해 응답 시간이 약 506.32 배 빨라졌고,
개선율은 99.80% 의 성능 개선이 이루어졌다!
현재 전체 조회 외에도, 검색 기능이 구현되어 있다.
해당 검색 기능은 키워드가 존재하기에 키워드를 인덱스로 적용하면 성능이 좋아지는지도 테스트해 추가해 볼 예정이다!