
위 영상을 보며 Redis의 내부 Event Loop가 어떻게 동작하는지 궁금해져서 Redis 코드를 따라가 보기로 결심했다.
GitHub - redis/redis: For developers, who are building real-time data-driven applications, Redis is the preferred, fastest, and
For developers, who are building real-time data-driven applications, Redis is the preferred, fastest, and most feature-rich cache, data structure server, and document and vector query engine. - red...
github.com
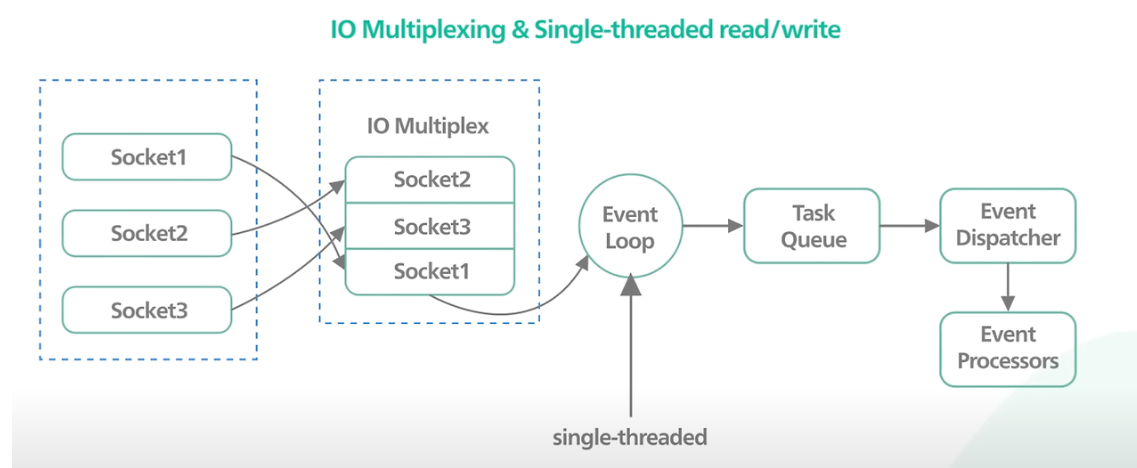
영상에선 위 그림이 Redis가 이벤트를 처리하는 구조라고 나와있다.
실제로 그런지 확인해 보자.
Redis가 이벤트를 처리하는 과정 큰 그림.
큰 그림을 먼저 그려보면 Redis는 다음과 같이 이벤트를 처리한다.
- 클라이언트와 Redis 간의 연결 수립(TCP)
- Redis의 메인 스레드는 각 운영체제에 맞는 I/O 멀티플렉싱 시스템콜을 통해, 커널로부터 읽기 또는 쓰기 준비가 된 FD의 리스트를 받는다.(I/O Multiplex 과정)
- Redis의 EventLoop는 전달받은 FD 리스트를 순차적으로 처리한다. FD의 이벤트 유형에 따라, 적절한 이벤트 핸들러 함수를 호출한다.
- 읽기(Read) 이벤트 처리
- 만약 해당 이벤트(FD)가 Read 상태라면, 해당 FD의 읽기 핸들러를 실행한다.(클라이언트의 명령어 - set, get etc - 를 파싱하고 실행)
- 명령어 실행이 완료되고, 클라이언트에게 보낼 응답 데이터가 준비되면, 응답 데이터를 출력 버퍼에 저장한다. 그리고 해당 클라이언트(FD)를 쓰기 리스트에 추가한다.
- 이벤트 루프가 한번 돌고 다음 이벤트 처리에 들어가기 전(beforeSleep 단계)
- 대기 중인 FD들에게 응답 데이터 전송을 시도한다.
- 전송에 실패하면 FD에 쓰기 이벤트 핸들러를 등록한다.
- 쓰기(Write) 이벤트 처리
- 만약 해당 이벤트 FD가 Write 상태라면, 해당 FD의 쓰기 핸들러를 실행하고, 응답 데이터를 클라이언트에게 전달한다.
- 읽기(Read) 이벤트 처리
1번 클라이언트와의 연결을 제외한 2, 3번이 Redis가 연결된 이벤트를 처리하는 과정이고, Redis가 실행되고, 종료되기 직전까지 무한루프를 돌며 2,3번을 반복한다.
여기서 무한루프를 돌면서 FD에 등록되어 있는 핸들러를 실행하는 Redis의 메인이벤트 처리 스레드는 1개만 존재한다. 이 메인 스레드가 모든 클라이언트 명령어를 순차적으로 처리하기 때문에 Redis를 싱글 스레드 모델이라고 한다.
(참고: Redis 6.0부터는 네트워크 I/O를 처리하는 별도의 I/O 스레드들이 추가되었지만, 실제 명령어 실행과 데이터 처리는 여전히 단일 메인 스레드에서 처리한다.)
아! 아직도 어렵다...
FD는 뭐고, 이벤트란 뭔지... , I/O 멀티플렉싱 등 여러 개념이 헷갈린다.
함께 공부해 가며 이해해 보자.
(이 글에선 클라이언트와 레디스 간의 연결 수립은 다루지 않는다.
연결이 수립되었다는 가정 하에, 이벤트를 어떻게 처리하는지 알아보자.)
1. IO Multiplex
Redis를 공부하면 IO Multiplex라는 말을 많이 보게 되고, 이게 여러 클라이언트 요청(이벤트)을 동시에 처리하는데 큰 역할을 한다고 배운다.
IO Multiplex란 여러 개의 소켓(연결)에서 발생하는 이벤트를 하나의 시스템 콜로 감지하는 기술이다.
클라이언트가 레디스에 연결을 요청하면 소켓이 생성된다.
그리고 각 클라이언트가 Redis에 이벤트를 발생시킨다. (여기서 이벤트란 특정 명령어(GET key, SET key value etc.)를 실행하는 것이라 보면 된다. 그 외에도 있는데, 해당 내용은 아래 이벤트루프를 설명할 때 나온다.)
즉, 시스템 콜이므로 각 OS에 따라 다르고, 개발자가 직접 개발하는 것이 아닌, 호출하는 것이다.
여러 소켓을 동시에 감시하고, 그중 I/O 작업(쓰기, 읽기)이 가능한 상태가 있다면, 해당 소켓과 발생한 이벤트 타입을 내부 배열(fired 배열에 저장)에 저장한다.
사실 소켓이란 네트워크 통신을 위한 추상적인 개념이다. 실제로 OS는 소켓을 다루기 위해 FD(File Discriptor)라는 정수값을 할당한다.
(클라이언트가 레디스와 연결이 되면, 각 클라이언트는 FD 값을 할당받는다. 그리고 Redis는 반복적으로 커널에 요청을 해서 기존 FD들 중에 이벤트가 준비된 것이 있다면, 해당 FD 값과 이벤트 타입을 Redis 내부 자료구조에 저장한다.)
모든 I/O 작업 또는 이벤트를 다루는 기준이 FD 값이 되므로, 엄밀히 말하면 I/O 멀티플렉싱은 소켓에 할당된 FD를 감시하는 것이다.
한 클라이언트와 레디스 간의 연결을 추상화하여 조금은 러프하게 추상화해 소켓이라 부를 수 있다.
이 소켓은 OS에서 FD(File Discriptor) 정수 값으로 표현된다.
그러므로 FD란 특정 소켓 연결을 가리키는 정수 인덱스이며, 하나의 클라이언트 연결당 하나의 FD가 할당된다.
(물론 새로운 연결이 들어오면, FD가 추가된다.)
이제부터 용어는 FD로 통일할 것이고, 이는 한 클라이언트와 서버 간의 연결을 의미하므로, 유의해서 읽으며 된다.
IO Multiplex 기술 덕분에 수많은 FD에서 발생하는 이벤트를 감지하고, 순차적으로 처리할 수 있게 된다.
그렇다면 어떻게 코드로 구현되어 있는지 살펴보자.
Redis 소스코드의 server.c의 int main() {} 함수를 보자.
이곳이 Redis의 진입점이다.
int main()의 마지막 즈음을 보면 다음과 같은 코드가 있다.
int main(int argc, char **argv) {
...
aeMain(server.el);
}
여기 aeMain이 이벤트 루프를 실행하는 함수이다.
(server.el은 이벤트 루프 객체로, server.c의 initServer() 함수에서 aeCreateEventLoop()를 호출하여 생성한다.)
// ae.c
...
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
...
aeProcessEvents를 따라가 보자.
// ae.c
...
// 아래는 각 운영체제에 따라 aeApiPoll 시 불러올 메서드를 결정하는 로직
#ifdef HAVE_EVPORT
#include "ae_evport.c" // Solaris
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c" // 리눅스
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c" // 맥
#else
#include "ae_select.c" // 모든 플랫폼
#endif
#endif
#endif
...
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
if (eventLoop -> maxfd != -1 || ((flas & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
numevents = aeApiPoll(eventLoop, tvp);
...
}
}
위 numevents = aeApiPoll(eventLoop, tvp); 가 IO Multiplex를 위한 코드이다.
aeApiPoll 함수로 따라가 보자.
// ae_epoll.c
...
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + (tvp->tv_usec + 999)/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE|AE_READABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE|AE_READABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
} else if (retval == -1 && errno != EINTR) {
panic("aeApiPoll: epoll_wait, %s", strerror(errno));
}
return numevents;
}
...(설명은 Linux를 기준으로 하기에, ae_epoll.c의 aeApiPoll()을 분석했다.)
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + (tvp->tv_usec + 999)/1000) : -1);여기 epoll_wait가 리눅스의 IO Mulitplex 시스템콜이다.
epoll_wait(2) - Linux manual page
epoll_wait(2) — Linux manual page epoll_wait(2) System Calls Manual epoll_wait(2) NAME top epoll_wait, epoll_pwait, epoll_pwait2 - wait for an I/O event on an epoll file descriptor LIBRARY top Standard C library (libc, -lc) SYNOPS
man7.org
epoll_wait()는 I/O 이벤트가 준비된 FD의 개수를 반환한다.
즉, 현재 I/O 요청이 들어온(이벤트가 준비된) FD의 개수를 반환하는 것이다. (retval = epoll_wait())
여기서 Redis의 효율성이 드러난다.
A call to epoll_wait() will block until either:
• a file descriptor delivers an event;
• the call is interrupted by a signal handler; or
• the timeout expires.
- epoll_wait()는 FD에 이벤트가 준비되었을 때
- 외부 시그널에 의해 시스템 콜(epoll_wait()이 인터럽트 되었을 때 (예 : ctrl+c로 레디스 종료)
- 타임아웃을 걸었을 경우, 해당 타임아웃이 만료되었을 때 (예: 직접 타임아웃 설정)
위 3가지 경우에만 실행이 되고, 그 외엔 블로킹되어 있다.
(즉, numevents = epoll_wait(); 에 멈춰있는 상태)
우리가 Redis에 특정 명령어를 보내 작업을 하지 않는다면, 아무것도 안 하고 있으므로, cpu 사용량이 없다.
다시 돌아가서, 아래 부분이 eventLoop가 처리할 fired 배열에 각 FD별 이벤트 타입을 등록하는 것이다.
// ae_epoll.c
/* 지금 I/O 요청이 들어온 FD가 있다면 실행 */
if (retval > 0) {
int j;
/* 현재 I/O 요청이 들어온 FD 수 */
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
/* j 번째 발생한 이벤트 정보 가져오기 */
struct epoll_event *e = state->events+j;
/* 읽기 가능하면 읽기 플래그 설정 */
if (e->events & EPOLLIN) mask |= AE_READABLE;
/* 쓰기 가능하면 쓰기 플래그 설정 */
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
/* 에러 발생 시 읽기/쓰기 모두 플래그 설정 */
if (e->events & EPOLLERR) mask |= AE_WRITABLE|AE_READABLE;
/* 연결 끊김 시 읽기/쓰기 모두 플래그 설정 */
if (e->events & EPOLLHUP) mask |= AE_WRITABLE|AE_READABLE;
/* 발생한 이벤트의 파일 디스크립터 저장 */
eventLoop->fired[j].fd = e->data.fd;
/* 발생한 이벤트의 마스크 저장 */
eventLoop->fired[j].mask = mask;
}
} else if (retval == -1 && errno != EINTR) {
panic("aeApiPoll: epoll_wait, %s", strerror(errno));
}
그리고 이벤트의 개수를 반환한다.
// ae_epoll.c
...
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
...
if (retval > 0) {
...
} else if (retval == -1 && errno != EINTR) {
...
}
return numevents;
}
...
즉, eventLoop는 계속해서 aeApiPoll을 호출하면서, 현재 I/O 요청이 들어온 FD가 있는지 반복적으로 확인한다.
만약 있다면 fired 배열에 저장된 FD와 이벤트를 순차적으로 처리한다.
이 과정이 IO Multiplex를 통해 여러 이벤트를 이벤트루프로 전달하는 과정이다.
2. EventLoop의 이벤트 처리
aeApiPoll()의 리턴값이 1 이상이라면, I/O 이벤트가 준비된 FD가 있다는 뜻이다.
FD는 2개의 이벤트 타입을 갖는다.
읽기 / 쓰기 이렇게 두 개의 이벤트 타입을 갖는데, 각각 다음 의미를 갖는다.
클라이언트 -> 레디스로 요청이 들어오는 경우는 Read Event이고,
레디스가 클라이언트의 요청을 처리하여 응답을 돌려주는 이벤트가 Write Event이다.
이를 유념하고 코드를 봐보자.
아래 aeProcessEvents()가 Redis의 이벤트 루프의 핵심으로, 여기서 이벤트를 처리한다.
/// ae.c
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
numevents = aeApiPoll(eventLoop, tvp); // 준비된 이벤트의 개수를 반환
...
/* 발생한 파일 이벤트들을 순차 처리 */
for (j = 0; j < numevents; j++) {
int fd = eventLoop->fired[j].fd;
aeFileEvent *fe = &eventLoop->events[fd];
int mask = eventLoop->fired[j].mask;
/* 현재 fd에서 실행된 이벤트 개수 */
int fired = 0;
...
/* 이벤트가 여전히 유효한지 "fe->mask & mask & ..." 로 확인
* 순서가 뒤바뀌지 않으면 읽기 이벤트 먼저 실행 */
if (!invert && fe->mask & mask & AE_READABLE) {
/* 읽기 이벤트 핸들러 함수(콜백함수) 실행 (예: 클라이언트 명령어 실행) */
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
fe = &eventLoop->events[fd]; // 콜백에서 배열 크기가 변경될 수 있으므로 포인터 갱신
}
/* 쓰기 이벤트 실행 */
if (fe->mask & mask & AE_WRITABLE) {
/* 같은 콜백 함수가 읽기와 쓰기에 모두 등록된 경우 중복 실행 방지 */
if (!fired || fe->wfileProc != fe->rfileProc) {
/* 쓰기 이벤트 콜백 실행 (예: 클라이언트 응답 쓰기) */
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
...
/* 처리된 파일 이벤트 개수 증가 */
processed++;
}
}
...
/* 처리된 총 이벤트 개수 반환 (파일 이벤트 + 타이머 이벤트) */
return processed;
}
처리할 이벤트가 있다면, 처리할 이벤트 개수(numevents)만큼 루프를 돌면서 이벤트를 처리한다.
/* numevents == 현재 이벤트가 준비된 FD의 개수
발생한 파일 이벤트들을 순차 처리 */
for (j = 0; j < numevents; j++) {
/* 처리할 파일 디스크립터(클라이언트를 의미) */
int fd = eventLoop->fired[j].fd;
/* 해당 fd에 대한 파일 이벤트 구조체 */
aeFileEvent *fe = &eventLoop->events[fd];
/* 발생한 이벤트 마스크(어떤 이벤트가 발생했는지) */
int mask = eventLoop->fired[j].mask;
...
}
그 후 해당 fd에 어떤 이벤트가 준비되어 있는지, 확인하고 이벤트를 처리한다.
아래는 aeFileEvent 구조체로, FD와 연결된 I/O 이벤트를 관리하기 위한 구조체이다.
typedef struct aeFileEvent {
/* 이벤트 마스크: AE_READABLE|AE_WRITABLE|AE_BARRIER 중 하나 또는 조합
* 어떤 종류의 I/O 이벤트를 감지할지 결정 */
int mask;
/* 읽기 가능 이벤트 발생 시 호출될 콜백 함수 */
aeFileProc *rfileProc;
/* 쓰기 가능 이벤트 발생 시 호출될 콜백 함수
* 클라이언트 응답 전송, 버퍼링된 데이터 출력 등에 사용 */
aeFileProc *wfileProc;
/* 콜백 함수에 전달될 사용자 정의 데이터
* 클라이언트 연결 정보 etc */
void *clientData;
} aeFileEvent;
아래 코드를 보면 fe(파일 이벤트)가 읽기 이벤트를 달고 있다면, 읽기 이벤트 핸들러 함수를 실행한다.
(invert 플래그가 있지만, 이벤트 처리에 중요한 로직은 아니므로 넘어가자.)
만약 fe에 달린 이벤트가 쓰기 이벤트라면 , 쓰기 이벤트 핸들러 함수를 실행한다.
/* 읽기 이벤트 실행
* AE_READABLE */
if (!invert && fe->mask & mask & AE_READABLE) {
/* 읽기 이벤트 핸들러 함수(콜백함수) 실행 (예: 클라이언트 명령어 실행) */
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
/* 콜백에서 배열 크기가 변경될 수 있으므로 포인터 갱신 */
fe = &eventLoop->events[fd];
}
/* 쓰기 이벤트 실행 */
* AE_WRITABLE */
if (fe->mask & mask & AE_WRITABLE) {
/* 같은 콜백 함수가 읽기와 쓰기에 모두 등록된 경우 중복 실행 방지 */
if (!fired || fe->wfileProc != fe->rfileProc) {
/* 쓰기 이벤트 콜백 실행 (예: 클라이언트 응답 쓰기) */
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
이렇게 이벤트를 처리하는 것이 Redis EventLoop의 핵심 로직이다.
이렇게 한 번의 루프를 돌고 다음 이벤트 처리 루프로 돌아왔을 때의 beforesleep을 살펴보자.
(beforesleep은 많은 역할을 하지만, 현재 내가 궁금한 것은 어떻게 클라이언트에게 응답을 전송하는지이므로, 해당 부분만 살펴보자)
// ae.c
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
...
/* 이벤트 대기 전 befroesleep 실행 */
if (eventLoop->beforesleep != NULL && (flags & AE_CALL_BEFORE_SLEEP))
eventLoop->beforesleep(eventLoop);
...
}
beforesleep()의 구현체는 server.c에 존재하므로, 따라가 보자.
// server.c
void beforeSleep(struct aeEventLoop *eventLoop) {
...
if (ProcessingEventsWhileBlocked) {
...
/* 클라이언트에게 쓰기 시도 */
processed += handleClientsWithPendingWrites();
...
return;
}
...
handleClientsWithPendingWrites();
...
}
handleClientsWithPendingWrites() 함수가 클라이언트에게 응답을 전송하는 부분이므로, 다시 따라가자.
// networking.c
int handleClientsWithPendingWrites(void) {
...
while((ln = listNext(&li))) {
...
/* Try to write buffers to the client socket. */
if (writeToClient(c,0) == C_ERR) continue;
/* If after the synchronous writes above we still have data to
* output to the client, we need to install the writable handler. */
if (clientHasPendingReplies(c)) {
installClientWriteHandler(c);
}
}
return processed;
}
Redis 코드 주석에도 나와있듯이, writeToClient가 클라이언트 소켓(FD)에 응답 버퍼를 적는 부분이라 한다.
즉, FD에 데이터를 전송하는 부분이다.
그리고 쓰기 작업을 시도한 후에도, FD에 보낼 데이터가 남아있다면, 쓰기 이벤트 핸들러를 해당 FD에 추가한다.
/* If after the synchronous writes above we still have data to
* output to the client, we need to install the writable handler. */
if (clientHasPendingReplies(c)) {
installClientWriteHandler(c);
}
마지막으로 writeToClient()로 들어가 어떻게 전송을 하는지 살펴보자.
// networking.c
int writeToClient(client *c, int handler_installed) {
...
ssize_t nwritten = 0, totwritten = 0; /* 이번 호출에서 쓴 바이트 수 */
/* 슬레이브 여부 */
const int is_slave = clientTypeIsSlave(c);
/* 슬레이브(복제본) 클라이언트 처리 */
if (unlikely(is_slave)) {
/* 슬레이브인지 아닌지 여부에 따라 다르게 처리 */
while(_clientHasPendingRepliesSlave(c)) {
int ret = _writeToClientSlave(c, &nwritten);
if (ret == C_ERR) break;
totwritten += nwritten;
}
atomicIncr(server.stat_net_repl_output_bytes, totwritten);
} else {
/* 일반 클라이언트 처리 */
const int is_normal_client = !(c->flags & CLIENT_SLAVE);
while (_clientHasPendingRepliesNonSlave(c)) {
int ret = _writeToClientNonSlave(c, &nwritten);
if (ret == C_ERR) break;
totwritten += nwritten;
...
}
atomicIncr(server.stat_net_output_bytes, totwritten);
}
...
return C_OK;
}
클라이언트가 slave인지 여부에 따라
_writeToClientSlave()
_writeToClientNonSlave()
이렇게 나눠서 응답을 전송한다.
두 함수를 살펴보면 어찌 됐든,
*nwritten = connWrite(c->conn, c->buf + c->sentlen, c->bufpos - c->sentlen);static inline int connWrite(connection *conn, const void *data, size_t data_len) {
return conn->type->write(conn, data, data_len);
}connection type(tcp 연결, tls 연결 등)에 따라 다르게 write가 달려있으므로, type에 맞게 write를 실행한다.
// connection.h
/* IO */
int (*write)(struct connection *conn, const void *data, size_t data_len);connection에 data 길이만큼 data를 보낸다는 뜻이다.
위 방식으로 데이터를 유저에게 전송한다.
이렇게 위 beforesleep() 이 끝난 후에야 Redis의 메인스레드가 epoll_wait()을 실행하고, epoll_wait()가 동작하는 3가지 경우를 제외하곤 잠든 상태로 대기한다.
이렇게 길었던 EventLoop의 동작 방식에 대해 알아보았다.
정리
우리는 위에서

이 부분만 살펴보았다.
그리고 코드를 전부 따라가 본 결과, Task Queue -> Event Dispatcher -> Event Processors 과정과 Redis가 이벤트를 처리하는 과정은 조금 다르다.
Redis는 Task Queue가 아닌 이벤트가 준비된 FD 배열을 받고, 해당 배열을 순차적으로 순회하며 각 이벤트 타입에 따라 이벤트 핸들러를 실행한다.
위 그림은 일반적인 이벤트 기반 아키텍처에 더 가깝고, Redis는 뒷 단계를 하나의 EventLoop에서 처리한다고 보면 된다.