클로바 스튜디오 엔진 튜닝하기(온라인, API)
큐시즘 밋업 프로젝트를 진행하며 AI 튜닝을 진행하게 되었다.
튜닝(모델 훈련)을 하는 방법을 찾아봤지만 다 비슷한 글에다 네이버에서 올라온 홍보와 비슷한 글 밖에 없었다.
잘하는 분들은 다 문서를 찾아보며 하겠지만... 나에겐 헷갈리는 과정이 많았기에 포스트로 정리해보려 한다!
(답답해서 내가 쓴다!)
학습 데이터 생성하기
https://clovastudio.ncloud.com/tuning/api
CLOVA Studio
clovastudio.ncloud.com
먼저 학습시킬 데이터를 만들어야 한다.
데이터의 경우 csv, json 파일로 만들어야 하는데, 우리 팀은 csv를 사용했다.

어떤 형식으로 AI를 사용할지에 따라 싱글턴인지 멀티턴인지가 결정된다.
만약 한 번의 질문으로 답을 얻어오는 경우라면 싱글턴(우리팀의 경우) ,
AI와 대화를 한다면 멀티턴으로 데이터 셋을 만들면 된다.
만약 파일 형식을 CSV로 할 예정이라면 아래 사이트에 들어가 데이터셋 템플릿을 다운받아 사용하면 된다.
싱글턴과 멀티턴에 대한 설명, 각 턴에 대한 데이터셋 예시도 존재하니 함께 보면 된다.
https://guide.ncloud-docs.com/docs/clovastudio-instructiondataset


중요한 부분이 있다. 튜닝의 경우 온라인과 API를 사용하는 방식이 존재한다.
온라인으로 튜닝을 할 예정이라면 C_ID, T_ID가 없어야 한다.
총 2개의 열이 존재해야 한다. (Text, Completion)
API 튜닝(하이퍼 클로바 X 모델)을 사용할 예정이라면 C_ID, T_ID가 있어야 한다.
총 4개의 열이 존재해야 한다. (C_ID, T_ID, Text, Completion)
기본적으론 C_ID, T_ID까지 다 적는 것을 추천한다.
온라인으로 훈련을 할 예정이라며, 아래 파이썬 코드로 C_ID와 T_ID를 다 삭제하고 진행하자!
import pandas as pd
df = pd.read_csv('dataset.csv')
df = df.drop(['C_ID', 'T_ID'], axis=1)
df.to_csv('dataset_removed_c_id_t_id.csv', index=False)
(read_csv() 안에는 데이터셋의 파일 이름이 들어가야한다. 당연히 파이썬 코드가 실행되는 위치와 csv 파일이 다르다면 위치까지 적어줘야 한다. )
온라인으로 튜닝하기
https://clovastudio.ncloud.com/tuning
CLOVA Studio
clovastudio.ncloud.com
(위 링크를 통해 온라인 튜닝이 가능하다.)
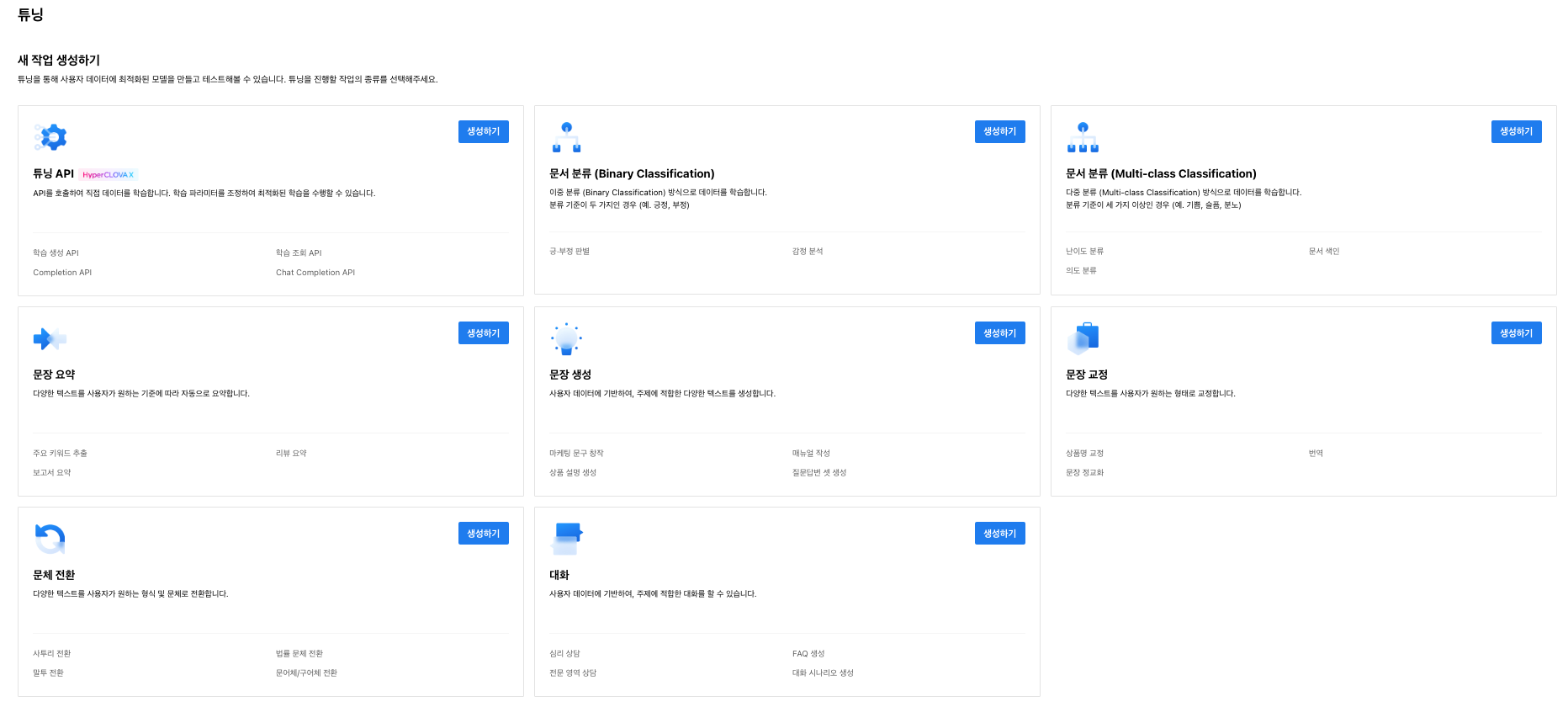
여러 작업이 존재하는데, 이 중 본인에게 필요한 작업을 생성하면 된다.
(튜닝 API를 제외하곤 모두 LK 모델을 사용한다. 성능은 HCP 모델이 더 좋다고 하는데, 필요한 기능이 하이퍼 클로바 X가 아니라면 LK 모델을 사용하는 것도 나쁘지 않다고 생각한다.)
예시로 봐보자!

모델 엔진을 선택하고 생성을 누르자.

온라인으로 튜닝을 할 경우, 데이터셋에 C_ID와 T_ID가 있다면 데이터셋에 업로드가 안되니 데이터셋을 업로드하기 전,
위에 있는 파이썬 코드를 통해 C_ID와 T_ID를 제거하자!
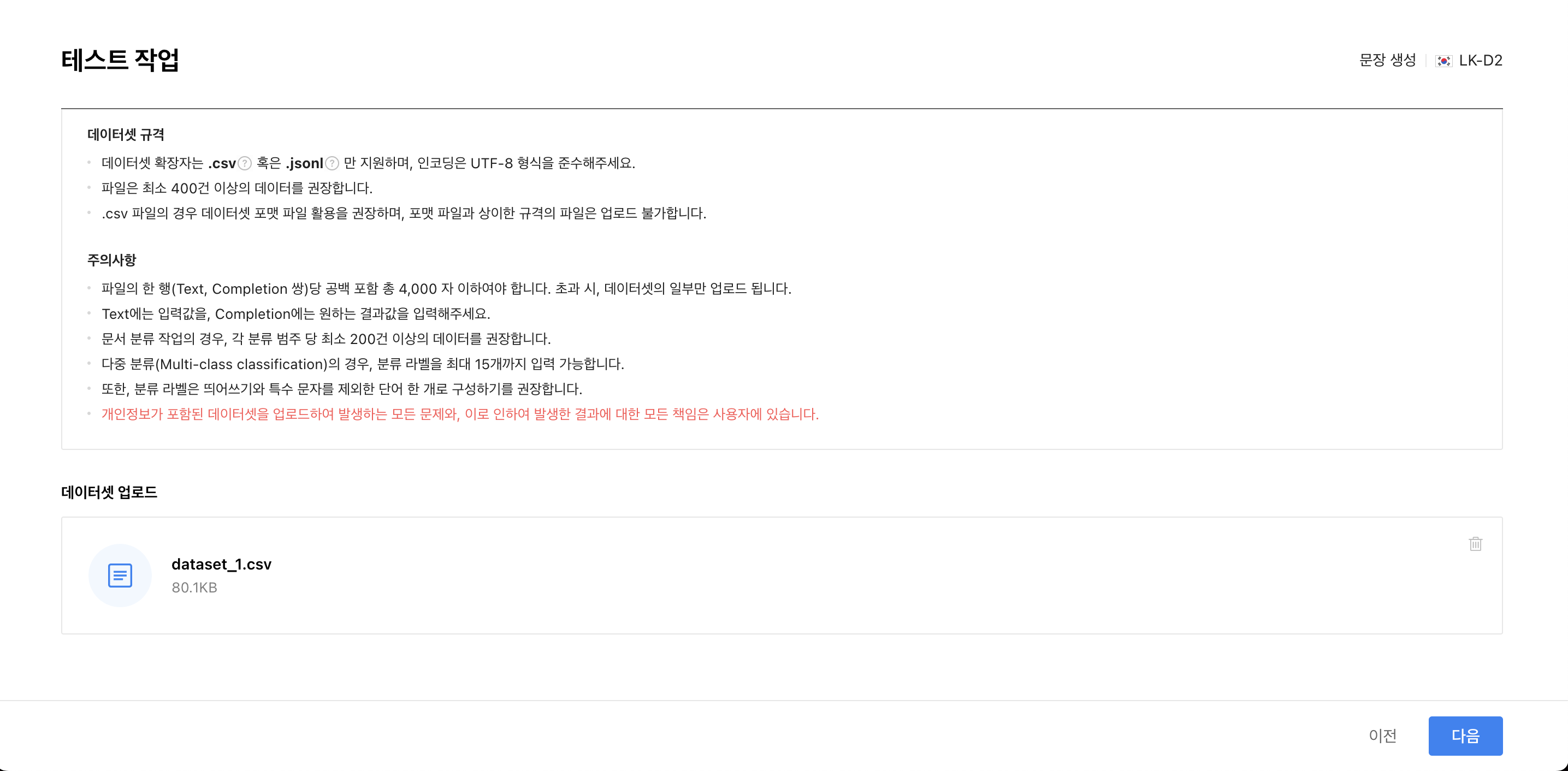

이렇게 데이터셋을 넣으면, 예상 토큰이 나온다.
학습을 누르면 아래와 같이 학습을 진행한다.
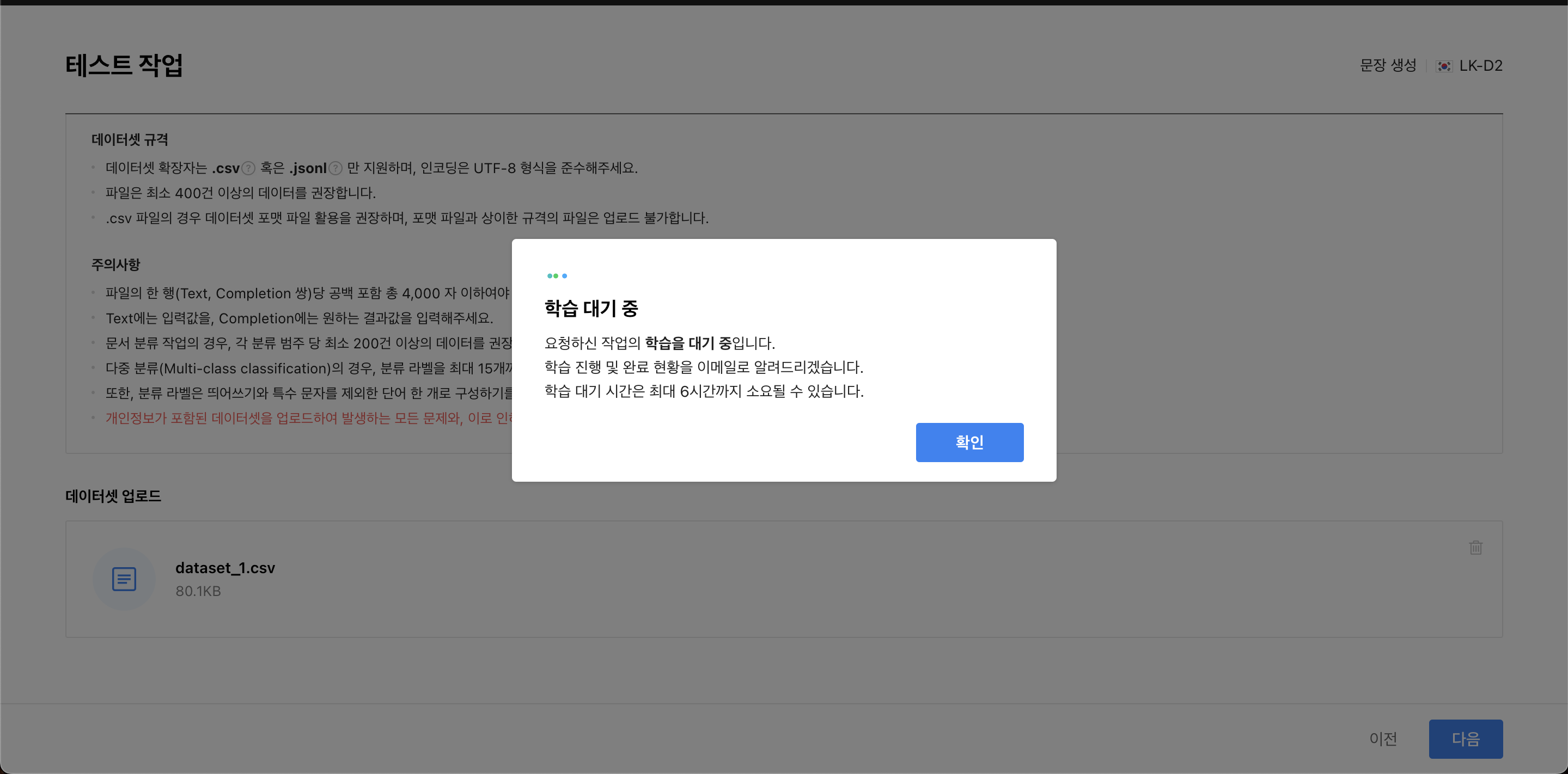
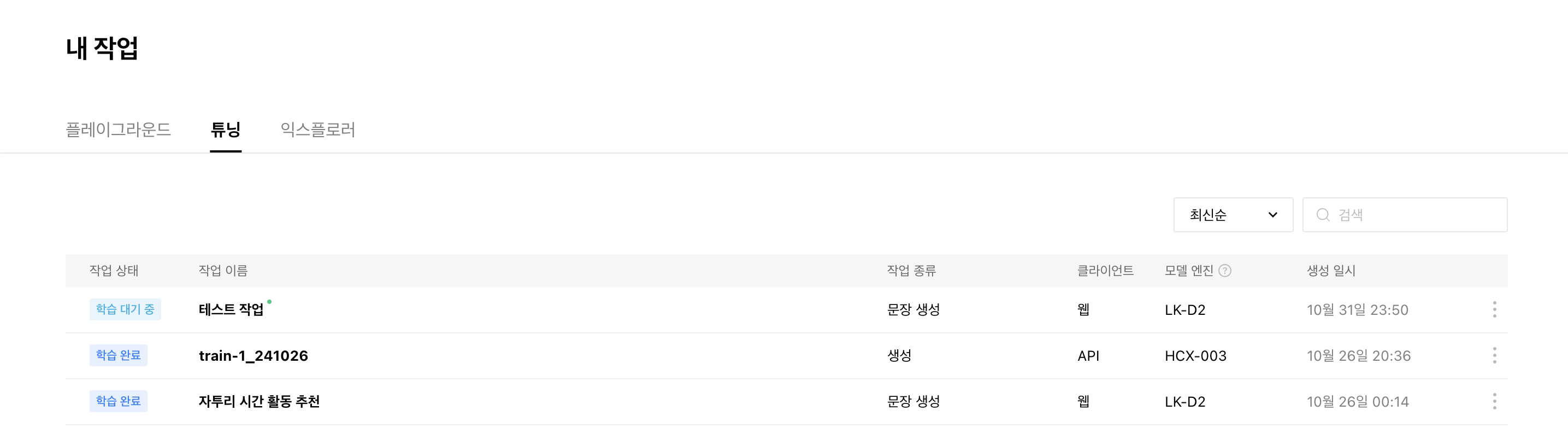

이렇게 학습을 시작하고 종료되면 메일이 온다!

학습이 완료되면 플레이그라운드로 이동해 학습시킨 모델을 활용할 수 있다!
API로 학습하기
그러나....
HCX(하이퍼 클로바 X)를 사용하고 싶을 수 있다!
HCX의 경우 API로 학습을 진행해야 한다.
아래 페이지에 들어가 학습 데이터를 어떻게 구성해야하는지 볼 수 있다. (온라인 튜닝과 크게 다른 점은 없다.)
https://clovastudio.ncloud.com/tuning/api
CLOVA Studio
clovastudio.ncloud.com
API를 통해 튜닝을 하기위해선 데이터셋을 Object Storage에 저장해야 한다.
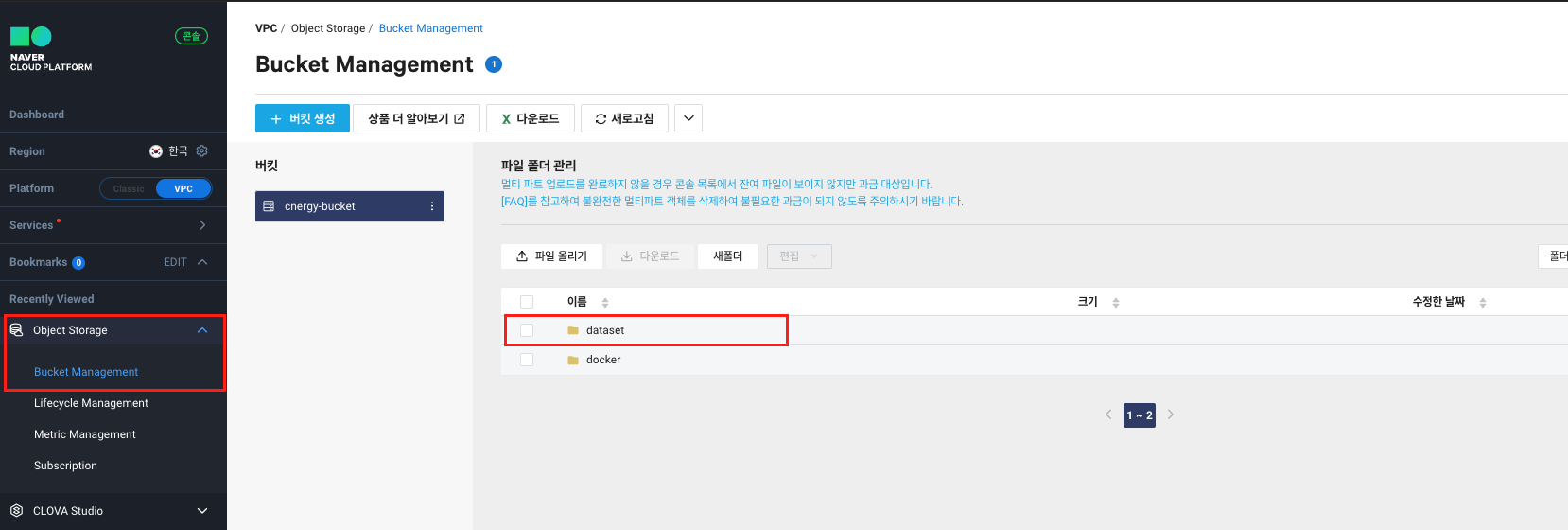

나의 경우 dataset이란 폴더를 만든 뒤 해당 폴더 안에 데이터셋을 저장했다.
현재 나의 데이터셋의 path는 무엇일까 ?
dataset/column_dataset_1.csv(cnergy-bucket안에 dataset 폴더 안에 있으니까...! cnergy-bucket은 안쓰나? 라고 궁금해할 수 있는데, path를 구할 땐 사용하지 않는다.)
이게 왜 중요하냐면...!
이 주소가 튜닝을 할 때 사용된다.
쨋든 이렇게 데이터셋을 저장했다.
튜닝을 위해 다음 파이썬 코드를 작성했다.
(나는 코랩을 통해 진행했다.)
# -*- coding: utf-8 -*-
import base64
import hashlib
import hmac
import requests
import time
class CreateTaskExecutor:
def __init__(self, host, uri, method, iam_access_key, secret_key, request_id):
self._host = host
self._uri = uri
self._method = method
self._api_gw_time = str(int(time.time() * 1000))
self._iam_access_key = iam_access_key
self._secret_key = secret_key
self._request_id = request_id
def _make_signature(self):
secret_key = bytes(self._secret_key, 'UTF-8')
message = self._method + " " + self._uri + "\n" + self._api_gw_time + "\n" + self._iam_access_key
message = bytes(message, 'UTF-8')
signing_key = base64.b64encode(hmac.new(secret_key, message, digestmod=hashlib.sha256).digest())
return signing_key
def _send_request(self, create_request):
headers = {
'X-NCP-APIGW-TIMESTAMP': self._api_gw_time,
'X-NCP-IAM-ACCESS-KEY': self._iam_access_key,
'X-NCP-APIGW-SIGNATURE-V2': self._make_signature(),
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id
}
result = requests.post(self._host + self._uri, json=create_request, headers=headers).json()
return result
def execute(self, create_request):
res = self._send_request(create_request)
if 'status' in res and res['status']['code'] == '20000':
return res['result']
else:
return res
if __name__ == '__main__':
completion_executor = CreateTaskExecutor(
host='https://clovastudio.apigw.ntruss.com',
uri='/tuning/v2/tasks',
method='POST',
iam_access_key='발급받은 Access Key',
secret_key='발급받은 Secret Key',
request_id='1(어떤 값이든 크게 상관없음)'
)
# 파일 및 데이터 요청
request_data = {
"name": "train-1_241026",
"model": "HCX-003",
"taskType" : "GENERATION",
"trainEpochs" : "8",
"learningRate" : "1e-5f",
"trainingDatasetFilePath": "데이터셋이 저장된 경로(objectStorage에서!)",
"trainingDatasetBucket": "데이터셋을 저장한 버킷 이름",
"trainingDatasetAccessKey": "발급받은 Access Key",
"trainingDatasetSecretKey": "발급받은 Secret Key"
}
response_text = completion_executor.execute(request_data)
print(request_data)
print(response_text)
https://api.ncloud-docs.com/docs/clovastudio-posttask
학습 생성
api.ncloud-docs.com
위 링크로 들어가면 코드의 각 부분에 어떤 값들이 들어가야 하는지 알 수 있다.
하지만... 나는 헷갈렸던 부분들이 있었기에 해당 부분을 정리해보겠다.

iam_access_key : 네이버 클라우드 플랫폼이나 Sub Account 서비스에서 발급받은 AccessKey를 입력한다.
secret_key : AccessKey에 해당하는 Secret Key 이다.
trainingDatasetFilePath : 위에서 데이터셋을 objectStorage에 저장했다. 그 때 path를 구했는데, 그 path를 넣으면 된다! (이 글 예시에선 dataset/column_dataset_1.csv )
trainingDatasetBucket : objectStorage에 bucket을 저장하면 된다.(이 글에선 cnergy-bucket)
trainingDatasetAccessKey : iam_access_key를 입력하면 된다.
trainingDatasetSecretKey : secret_key를 입력하면 된다.
혹시라도 iam_access_key와 secret_key를 어디서 구하는지 헷갈릴 수 있으니까 아래 화면에서 확인할 수 있다.
NCP 콘솔 -> 우상단 본인 이름 클릭 -> 계정 관리 -> 인증키 관리
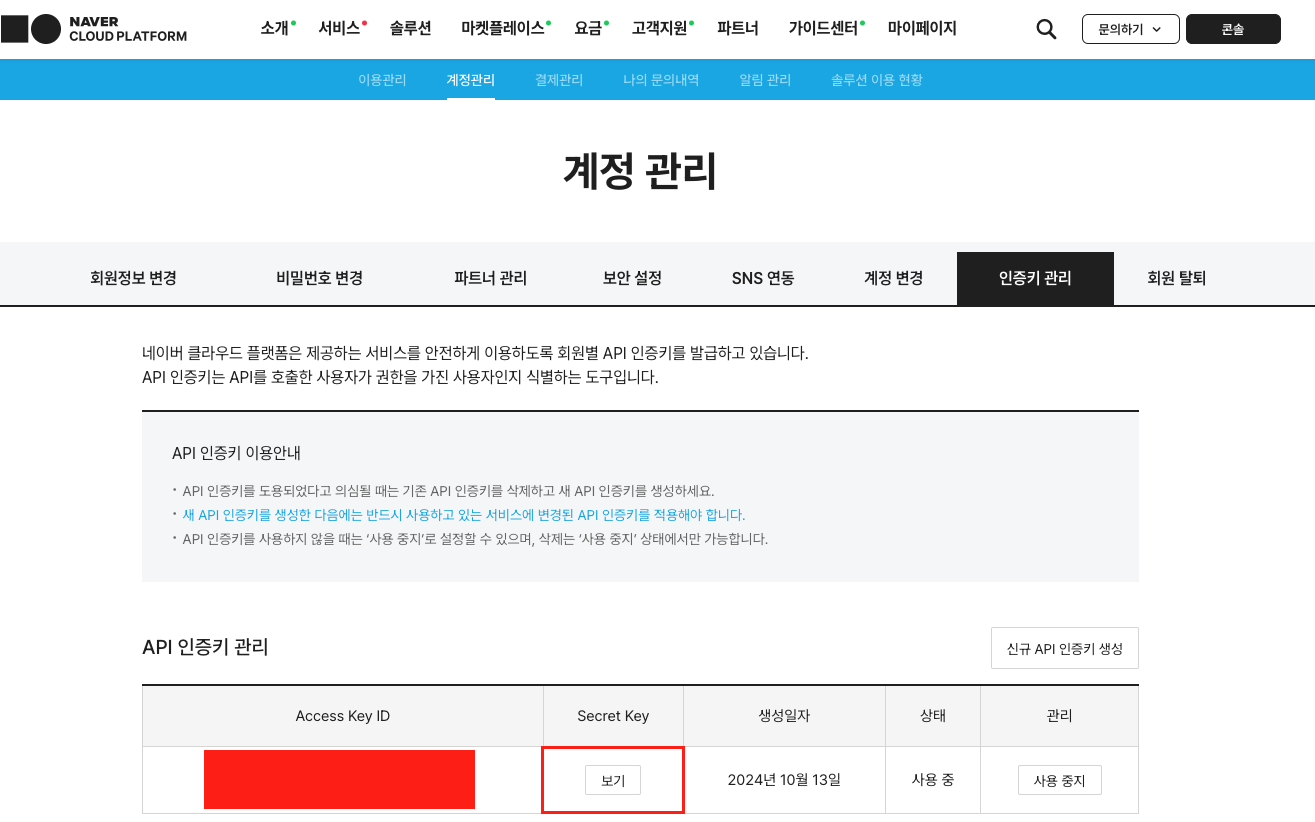
이제 학습 코드의 값을 다 채울 수 있다!

이후 코드를 실행시키면 학습이 시작된다!

학습이 제대로 진행되는지 궁금하니까 학습 조회 코드도 작성해보자.
# -*- coding: utf-8 -*-
import base64
import hashlib
import hmac
import requests
import time
class FindTaskExecutor:
def __init__(self, host, uri, method, iam_access_key, secret_key, request_id):
self._host = host
self._uri = uri
self._method = method
self._api_gw_time = str(int(time.time() * 1000))
self._iam_access_key = iam_access_key
self._secret_key = secret_key
self._request_id = request_id
def _make_signature(self, task_id):
secret_key = bytes(self._secret_key, 'UTF-8')
message = self._method + " " + self._uri + task_id + "\n" + self._api_gw_time + "\n" + self._iam_access_key
message = bytes(message, 'UTF-8')
signing_key = base64.b64encode(hmac.new(secret_key, message, digestmod=hashlib.sha256).digest())
return signing_key
def _send_request(self, task_id):
headers = {
'Content-Type': 'application/json; charset=utf-8',
'X-NCP-APIGW-TIMESTAMP': self._api_gw_time,
'X-NCP-IAM-ACCESS-KEY': self._iam_access_key,
'X-NCP-APIGW-SIGNATURE-V2': self._make_signature(task_id),
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id
}
result = requests.get(self._host + self._uri + task_id, headers=headers).json()
return result
def execute(self, taskId):
res = self._send_request(taskId)
if 'status' in res and res['status']['code'] == '20000':
return res['result']
else:
return res
if __name__ == '__main__':
completion_executor = FindTaskExecutor(
host='https://clovastudio.apigw.ntruss.com',
uri='/tuning/v2/tasks/',
method='GET',
iam_access_key='발급받은 AccessKey',
secret_key='발급받은 SecretKey',
request_id='2'
)
taskId = '학습 코드를 진행했을 때 응답으로 taskId가 온다.'
response_text = completion_executor.execute(taskId)
print(taskId)
print(response_text)taskId는 처음 학습 코드를 실행시켰을 때 반환되는 값들 중 id에 해당하는 값이다.

이렇게 학습 조회 코드를 완성하고 다시 실행하면 학습이 어떤 상태인지 확인할 수 있다.
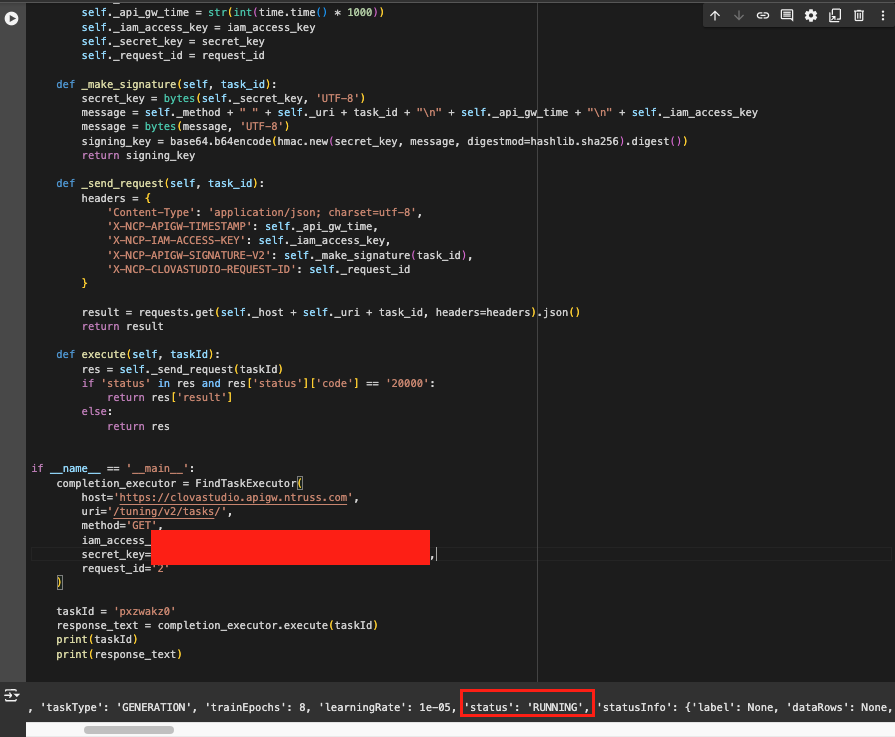
API로 튜닝을 하면 네이버 메일로도 학습중이라 메일이 오니까 메일을 확인해도 된다!
학습이 다 완료되면 플레이그라운드에서 학습된 모델을 사용할 수 있다!

본인이 원하는 모델에 따라 튜닝 방법이 달라지니, 모델에 맞게 튜닝을 진행하면 된다!
끝~!
(혹시라도 안되는 부분이 있으면 댓글 달아주시고, 틀린 설명이 있다면 지적해주세요~!)